牛客刷题记录2
Hash和History的区别
Hash路由
hash模式的工作原理是hash change事件,可以在windows监听hash变化。我们在url后面随便添加一个#xx触发这个事件
vue-router默认的是hash模式使用URL的hash来模拟完整的一个URL,当URL改变的时候,页面不会重新加载,也就是单页应用了,当后面hash发生变化,不会导致浏览器向服务器发出请求,浏览器不发出请求,就不会刷新页面,并且会触发hashChange这个事件,通过监听hash值的变化来实现更新页面部分内容的操作。
对于hash模式会创建hashhistory对象在访问不同路由的时候会发生俩件事
HashHistory.push()将新的路由添加到浏览器访问的历史栈顶,和HashHistory.replce()替换到当前栈顶路由
history路由
通过history.push使它做页面跳转不会出发页面刷新,使用window.onpopstate监听浏览器的前进和后退,再做其他处理
每当激活同一文档中不同的历史记录条目时,popstate事件就会在对应的window对象上触发。如果当前处于激活状态的历史记录条目是由history.pushState()方法创建的或是history.replaceState()方法进行修改的,则popstate事件的state属性包含了记录条目的state对象的一个拷贝
调用 history.pushState() 或者 history.replaceState() 不会触发 popstate 事件。popstate 事件只会在浏览器某些行为下触发,比如点击后退按钮(或者在 JavaScript 中调用 history.back() 方法)。即,在同一文档的两个历史记录条目之间导航会触发该事件。
hash模式下url会带有#,需要url更优雅时,可以使用history模式。
需要兼容低版本的浏览器时,建议使用hash模式。
需要添加任意类型数据到记录时,可以使用history模式。
延伸
前端路由的出现要从 ajax 开始,有了 Ajax 后,用户交互就不用每次都刷新页面,体验带来了极大的提升。随着技术的发展,简单的异步已经不能满足需求,所以异步的更高级体验出现了——SPA(单页应用)。 SPA 的出现大大提高了 WEB 应用的交互体验。在与用户的交互过程中,不再需要重新刷新页面,获取数据也是通过 Ajax 异步获取,页面显示变的更加流畅。 但由于 SPA 中用户的交互是通过 JS 改变 HTML 内容来实现的,页面本身的 url 并没有变化,这导致了两个问题:
• SPA 无法记住用户的操作记录,无论是刷新、前进还是后退,都无法展示用户真实的期望内容。
• SPA 中虽然由于业务的不同会有多种页面展示形式,但只有一个 url,对 SEO 不友好,不方便搜索引擎进行收录。
前端路由就是为了解决上述问题而出现。
圣杯布局和双飞翼布局
神隔壁布局和双飞翼布局是一回事,它们实现的都是三栏布局,俩边的盒子宽度固定,中间盒子自适应,也就是我们常说的固比固布局。他们的实现效果是一样的
双飞翼布局
如果把三栏布局比作一只鸟,可以把main看成是鸟的身体,left和right则是鸟的翅膀。这个布局的思路是先把重要的身体布局放好,然后再把翅膀移动到适当的地方
圣杯布局
- 圣杯布局是俩便固定宽度,中间自适应的三栏布局
- 中间栏放到文档流前面,先行渲染
- 目的是为了解决三栏布局
实现方式很多可以使用定位也可以使用浮动,弹性盒子实现比较简单
和双飞翼布局大同小异,区别于在堆遮挡中间栏的处理方式,圣杯为父元素设置padiding,然后相对定位把左右俩部分拉会原位
双飞翼则是直接对中间部分设置margin,把左右俩边拉会原位
浏览器输入URL后发生了什么
- 用户输入url会使用浏览器默认的搜索引擎加上搜索内容合成url,如果是域名会加上协议合成完整的URL(如https)合成完整的URL
- 然后按下回车。浏览器进程通过进程间通信把url传给网络进程(网络进程接收到url才发起真正的网络请求)
- 网络进程接受到url后,先查找有没有缓存,有缓存直接返回缓存的资源地址,没有缓存直接发起真正的网络请求
- 首先获得域名IP地址和服务器简历TCP连接(三次握手)
- 简历连接后,浏览器构建数据包(请求行,请求头,请求正文,并把改域名相关的cookie等数据附加到请求头)然后想服务器发送请求消息
- 服务器接受得到请求消息后根据请求信息构建响应数据(响应行,响应头,响应正文)然后发送回网络进程
- 网络进程接收到数据后进行解析,如果发现状态码为301,302说明服务器要进行重定向
- 数据传输完成,tcp四次挥手断开连接。
- 网络进程将获取到的数据包进行解析,根据响应头中的content-type来判断响应数据类型(如果是字节类型,就将请求交给下载管理器,流程结束,不是就通知浏览器进程进行渲染)
- 如果有数据一切正常,当浏览器拿到服务器的数据后,开始渲染页面的同时获取html中的图片音频,视频,css,js等文件
- 这期间获取到js会直接执行js代码,阻塞浏览器进行渲染,因为渲染引擎和js引擎互斥,通常把script标签放在body的底部
- 渲染的过程就是先将html转换成dom树,再将css样式转换为stylesheet,根据dom树和stylesheet创建布局树
- 对布局树进行分层。为每个图层生成绘制列表,再将图层分成图块,紧接着光栅化将图块转成位图,最后合成绘制生成页面
数组和伪数组
对象与数组的关系
在说区别之前,需要先提到另外一个知识,就是JavaScript的原型继承。所有JavaScript的内置构造函数都是继承自 Object.prototype。在这个前提下,可以理解为使用 new Array() 或 [] 创建出来的数组对象,都会拥有 Object.prototype 的属性值。
var obj = {};
var arr = [];
obj[2] = 'a';
arr[2] = 'a';
console.log(obj[2]); // 输出 a
console.log(arr[2]); // 输出 a
console.log(obj.length); // 输出 undefined
console.log(arr.length); // 输出 3通过上面这个测试,可以看到,虽然 obj[2]与arr[2] 都输出'a',但是,在输出length上有明显的差异,这是为什么呢?
- obj[2]输出'a',是因为对象就是普通的键值对存取数据
- 而arr[2]输出'a' 则不同,数组是通过索引来存取数据,arr[2]之所以输出'a',是因为数组arr索引2的位置已经存储了数据
- obj.length并不具有数组的特性,并且obj没有保存属性length,那么自然就会输出undefined
- 而对于数组来说,length是数组的一个内置属性,数组会根据索引长度来更改length的值。
伪数组
1、拥有length属性,其它属性(索引)为非负整数(对象中的索引会被当做字符串来处理,这里你可以当做是个非负整数串来理解)
2、不具有数组所具有的方法
伪数组,就是像数组一样有 length 属性,也有 0、1、2、3 等属性的对象,看起来就像数组一样,但不是数组,比如
var fakeArray = {
length: 3,
"0": "first",
"1": "second",
"2": "third"
};
for (var i = 0; i < fakeArray.length; i++) {
console.log(fakeArray[i]);
}
Array.prototype.join.call(fakeArray,'+');常见的参数的参数 arguments,DOM 对象列表(比如通过 document.getElementsByTags 得到的列表),jQuery 对象(比如 $("div"))。
伪数组是一个 Object,而真实的数组是一个 Array
fakeArray instanceof Array === false;
Object.prototype.toString.call(fakeArray) === "[object Object]";
var arr = [1,2,3,4,6];
arr instanceof Array === true;
Object.prototype.toString.call(arr) === "[object Array]"js的import和export
在理想情况下,开发者只需要实现核心的业务逻辑,其他都可以加载别人已经写好的模块。但是,javascript不是一种模块化的编程语言,在ES6以前,它是不支持类,所以也就没有模块的。在ES6标准发布后,module成为标准,标准都是以export指令导出接口,以import引入模块,但是在node模块中,我们依然采用的是CommonJS模块哦规范,使用require引入模块,使用module.exports导出接口
export导出模块
export语法声明用于导出函数,对象,指定文件(或模块)的原始值
export有俩种模块导出方式:命名式导出和默认导出
命名式每个模块可导出多个,而默认每个模块只有一个
import
import 语法用于从已导出的模块、脚本中导入函数、对象、指定文件(或模块)的原始值。
import 模块导入与 export 模块导出功能相对应,也存在两种模块导入方式:命名式导入(名称导入)和默认导入(定义式导入)。
import 的语法跟 require 不同,而且 import 必须放在文件的最开始,且前面不允许有其他逻辑代码,这和其他所有编程语言风格一致。
import defaultMember from "module-name";
import * as name from "module-name";
import { member1 } from "module-name";
import { member as alias } from "module-name";
import { member1 , member2 } from "module-name";
import { member1 , member2 as alias2 , [...] } from "module-name";
import defaultMember, { member1 [ , [...] ] } from "module-name";
import defaultMember, * as name from "module-name";
import "module-name";defaultMember 导入默认导出成员
name 从将要导入模块中收到的导出值的名称
member1,member1 导入指定名称的多个成员
alias 别名,对指定导入成员进行的重命名
module-name 要导入的模块,是一个文件名
as 重命名导入成员名称
from 从已经存在的模块、脚本文件等导入
原生对象,宿主对象的区别
原生对象
原生对象包括内置对象和本地对象,内置对象是包括了一些在运行过程中动态创建的对象
本地对象定义为独立于宿主环境的ECMAscropt提供的对象,包括Object、Function、Array、String、Boolean、Number、Date、RegExp
内置对象是独立于宿主环境的对象,ECMA262之定义了两个内置对象Global和Math
Global(全局)对象是ECMAScript中一个特别的对象,因为这个对象是不存在的。在ECMAScript中不属于任何其他对象的属性和方法,都属于它的属性和方法。所以,事实上,并不存在全局变量和全局函数;所有在全局作用域定义的变量和函数,都是Global对象的属性和方法。
PS:因为ECMAScript没有定义怎么调用Global对象,所以,Global.属性或者Global.方法()都是无效的。(Web浏览器将Global作为window对象的一部分加以实现)
Global对象是ECMAScript中最特别的对象,因为实际上它根本不存在!在ECMAScript中,不存在独立的函数,所有函数都必须是某个对象的方法。
类似于isNaN()、parseInt()和parseFloat()方法等,看起来都是函数,而实际上,它们都是Global对象的方法。而且Global对象的方法还不止这些。
宿主对象
ECMAscript主要在这个宿主的概念上,ECMAScript中的宿主当然就是我们网页的运行环境,
何为“宿主对象”? ECMAScript中的“宿主”当然就是我们网页的运行环境,即“操作系统”和“浏览器”。所有非原生对象都是宿主对象(host object),即由 ECMAScript 实现的宿主环境提供的对象。
所有的 BOM 和 DOM 对象都是宿主对象。因为其对于不同的“宿主”环境所展示的内容不同。其实说白了就是,ECMAScript官方未定义的对象都属于宿主对象,因为其未定义的对象大多数是自己通过ECMAScript程序创建的对象。TML DOM 是 W3C 标准(是 HTML 文档对象模型的英文缩写,Document Object Model for HTML)。
HTML DOM 定义了用于 HTML 的一系列标准的对象,以及访问和处理 HTML 文档的标准方法。
通过 DOM,可以访问所有的 HTML 元素,连同它们所包含的文本和属性。可以对其中的内容进行修改和删除,同时也可以创建新的元素。
js数据的拷贝方法
- 通过jsona暴力转换
- 使用扩展运算符+解构赋值
- 使用对象合并Object.assign()
- 遍历和递归对象
什么是V8引擎
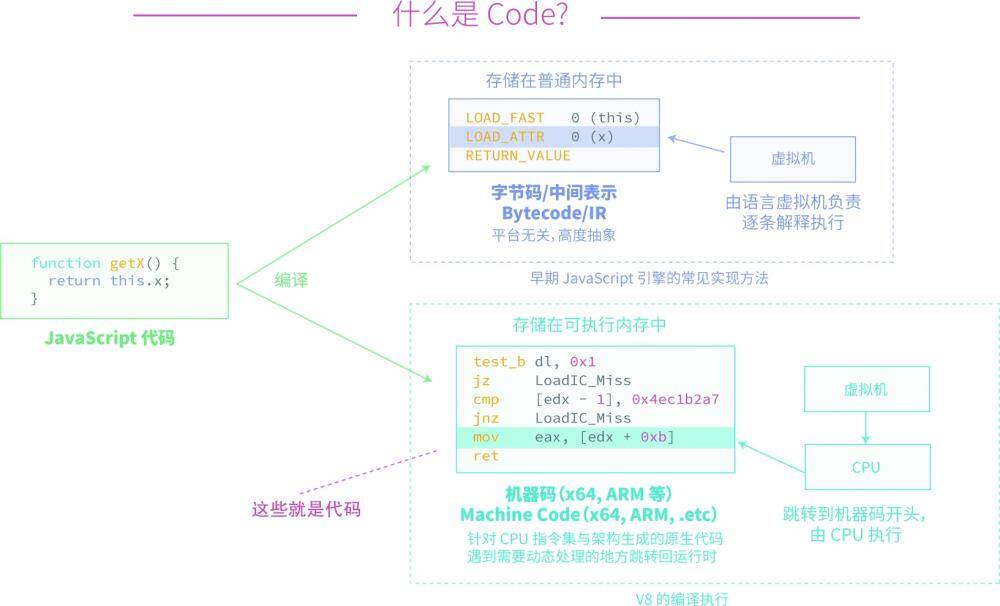
V8是google开源的javascript和webAssembly引擎,用c++编写。用于Node.js和chrome等,V8实现了ECMAscropt,进而WebAssembly。V8可以独立运行,也可以嵌入到任何C++应用程序中
V8使用后C++开发,并在谷歌浏览器中使用。在运行javascript,之前,相比于掐的javascript的引擎转换成字节码或解释执行,V8将其编译成原生机器码。并使用了内联缓存(inline caching),等方法来提高性能。
编译执行
V8引擎的性能保证来源于其内置的JavaScript编译器,V8采用的编译执行策略是JavaScript从服务端完成加载后,预先对所有的JavaScript代码进行编译
如果分析V8的源代码,可以发现V8仍然有类似java字节码的中间过程,但是从外部看,V8是直接将JavaScript编译成本地机器语言的。执行过程中编译器不再对过程进行干预。V8的解释与执行是俩个不同的部分
但是像JavaScript这种脚本语言有一个不同于编译语言的特点,就是它的弱类型,换句话说,某个变量属于哪种类型,只有在JavaScript语言运行过程中才能确定
V8的编译器为解释这种问题,引入了内联缓存技术来加速这类在编译期不能被优化的代码
举一个简单的例子,下面是一个 JavaScript 读取属性的例子:
function f(v) { return v.x; }对于V8的编译器来说,仅仅通过静态编译过程无从得知,是要读取一个对象自己的属性,还是原型对象的属性,还是一个getter方法,或者浏览器的某些自定义回调,这个属性还可能根本不存在
如果V8在编译的代码中处理这些所有情况,即时一个简单的操作也会引发上百条指令。为了优化这种情况,V8引擎需要对这个操作进行猜测。
V8引擎引入了内联缓存机制,将猜测最可能的几个方法,放到内联缓存中(类似处理器使用高速缓存来提高指令命中率)如果猜对了V8就能大大提高访问速度,如果如果没猜对,那么继续寻找,执行并发现正确方法,这样的访问代价也不是很高。
V8引擎详解(五)——内联缓存 - 掘金 (juejin.cn)
垃圾回收
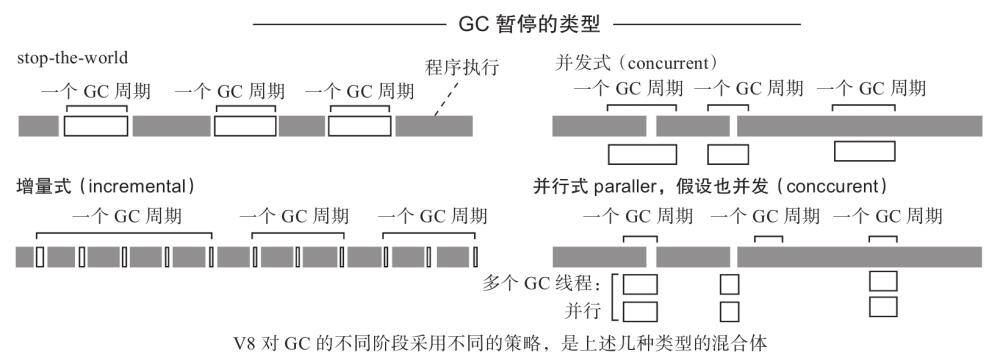
V8 - Orinoco(垃圾回收) - 知乎 (zhihu.com)
Vue和MVVM
M模型(Model)数据模型,负责数据存储。泛指后端进行的各种业余逻辑处理和数据操控,主要围绕数据库系统展开
V就是view视图,负责页面展示,也就是用户页面。主要又HTML和CSS来构建
VM就是视图模型(View-Model)负责处理业务逻辑,对数据加工后交给视图进行展示,通过vue类创建的对象叫vue实例化对象,这个对象就是MVVM模式中的VM层,模型通过它可以将数据绑定到页面上,视图可以通过它将数据映射到模型上
为什么说VUE是一个渐进式的javascript框架, 渐进式是什么意思?
渐进式的概念是分层设计,每层可选,不同层可灵活介入其他方案
VUE允许你将一个网页分割成可复用的组件,每个组件都包含属于自己的HTML、CSS、JAVASCRIPT以用来渲染网页中相应的地方。对于VUE的使用可大可小,它都会有相应的方式来整合到你的项目中。所以说它是一个渐进式的框架。
举个例子,我们要买一台电脑,店家给我们提供了一个IBM。
官方可能会提供windows作为可选,我们也可以在电脑上安装我们自己喜欢的Ubuntu。
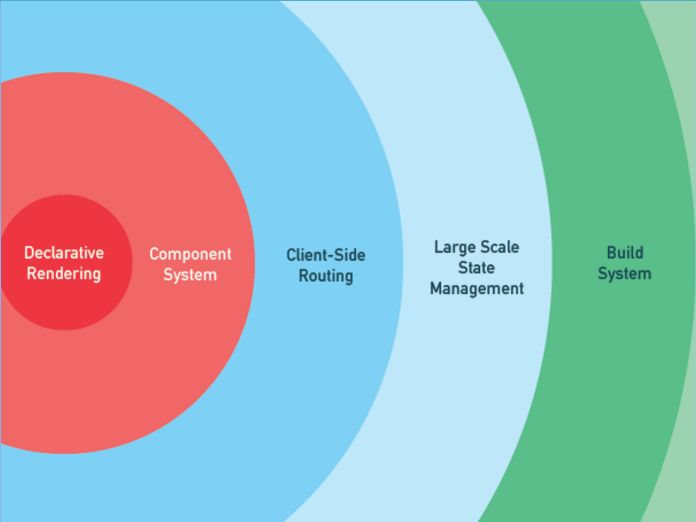
- declarative rendering(声明式渲染)
- component system(组件系统)
- client-side routing(前端路由)
- state management(状态管理)
- build system(构建系统)