离线混部
知乎k8s在离线混部-在线篇 - 知乎 (zhihu.com)
什么是理线混部
问题
在实现离线混部的过程中,在线环境必然面对以下5个问题:
- 在离线任务混部过程中,如何保证节点的均衡调度,否则因为不均衡对生产业务会造成一些延迟,甚至会有故障。
- 在任务运行过程中,如何实现节点的过载保护。具体而言,在运行过程中,协调节点的实时利用率。运行过程中会有过载情况,这个时候就需要考虑协调节点的实时利用率,避免生产业务会造成一些延迟,甚至会有故障。这一块会包含很多,例如网络、IO、Memory、CPU等。
- 在离线混部过程中,如何保证在线任务的稳定运行。由于离线任务对资源消耗会比较高,从而就要考虑对CPU&Memory的隔离和争抢情况。这一块争抢会牺牲离线脚本的实效,优先分配在线保障在线应用。通常情况会将应用做多个分级,优先保障高级别。这一块知乎将应用分为三类: BE类(对应离线应用,延迟非敏感,QOS对应BestEffort),LS类(对应在线应用,延迟敏感型业务,QOS对应Burstable), LSR(对应延迟敏感型业务, QOS 对应Guaranteed,绑核类业务)。
- 如何在离线任务运行完成后,保证资源的稳定回收。例如文件系统cache,如果一直占用Page cache,不释放。容易造成OOM,以及资源分配不足问题。
- 如何进行干扰保护。对于一些敏感型的应用来说,如果遇到对CPU对争抢比较严重,就要考虑干扰调度。可以把干扰过大的敏感型应用调度到干扰过小的节点。
成本优化方法
说到成本优化,对于知乎而言并不是一个早期阶段。知乎用K8S比较早,在2016年左右就开始使用K8S。那么来谈谈基于K8S背景下的一些手段。 在这一块我总结了一下大概有4种,分别为: 系统化资源利用提升、静态资源潮汐调度、动态资源潮汐调度、在离线混部。当然这些手段也是分很多阶段的、不同阶段使用不同的方式。
系统资源利用率提升
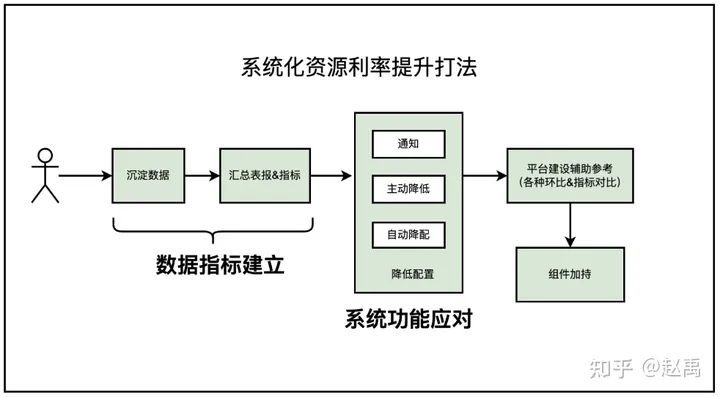
说到系统化资源利用,其实是整顿资源利用率比较早的一种手段。如图,做这件事情之前需要建立完善的数据指标、应用指标。通过指标通知应用放,自动或主动降配置。这种只适合早期、在资源利用率不合理的情况下最有效的手段。再这个阶段做不到资源的最优应用,并且光靠原生Kubernetes组件会存在的一些问题。
- 由于在线业务的多远化,会分为时延敏感性业务和非时延敏感型业务。彼此之间相互干扰,虽然通过标签区分隔离但是又会带来其他问题,例如由隔离带来的碎片填充问题,浪费多余的资源。
- Kubernetes调度不均衡、存在资源碎片问题、机器的实际利用率也不均衡,主要原因是原生的Kubernetes是kube-scheduler是按照pod的request进行调度,并不是真实资源使用(是按照所需资源,而不是真实资源)
静态资源潮汐调度介绍
说道静态资源潮汐调度,其实好比一个集群有4k台node节点资源,但是资源不会变动。但是潮汐并不适用于没有波峰波谷的业务类型。所以要合理的使用Kubernetes的VPA、HPA组件,再低峰的时候缩容、高峰的时候扩容。
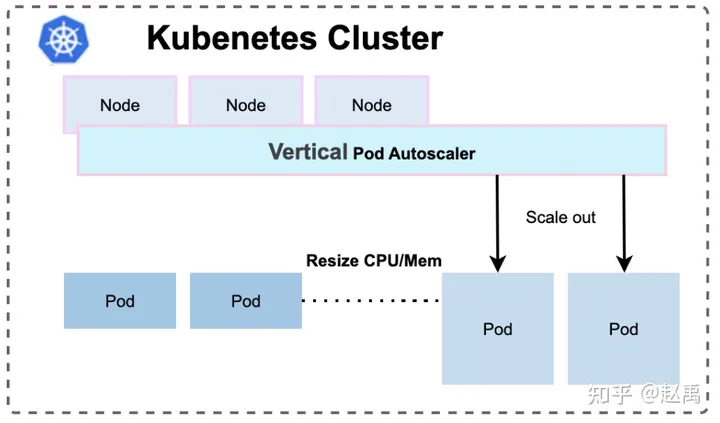
如图3-2所示、可以通过VPA纵向的伸缩pod的CPU和Memory,例如原来pod的CPU是10,低峰时缩成5。VPA经过改造后可以在不重建pod的情况伸缩CPU和Memory.
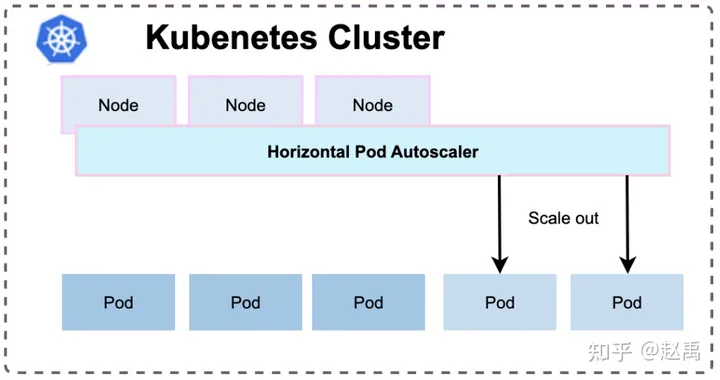
其次就是通过HPA横向扩容的方式,伸缩pod个数。VPA与HPA在潮汐应用上起到一定作用,因为要在低峰期降低配置,K8s才哭有效的调度应用。这样低峰期就调用一些理线服务或者是job类应用填充低峰,提升资源利用率。潮汐调度属于一个中期阶段,但是它也会存在一些缺陷,例如存在隔离资源池时,伸缩的意义并不是很大,碎片话反而会严重。当然会存在同node节点资源相互干扰的情况。
隔离资源池是一种将资源划分为不同的池子或区域,每个池子或区域都有自己的资源配额和限制。这种资源隔离的目的是为了确保不同的工作负载之间互相不会干扰,从而增加系统的可靠性和稳定性。
动态资源潮汐调度
动态资源潮汐调度顾名思义,其实就是节点可以伸缩。Kubernetes官方本身是支持节点伸缩功能,也就是CA调度器(Cluster autoscaler)
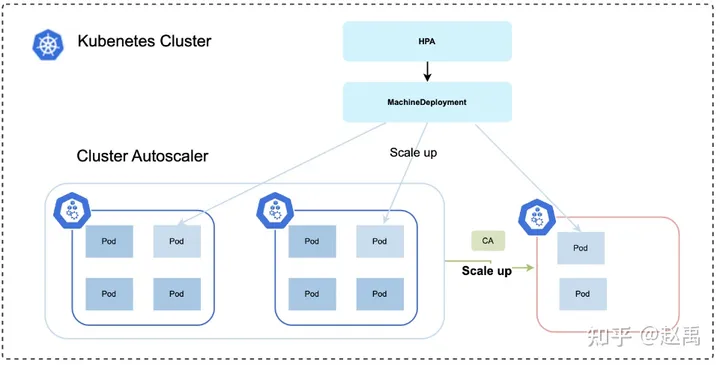
CA调度器可以通过MachineDeployment资源扩充对应的节点,对应云厂商节点池功能。但是本身而言需要做到潮汐调度,就要有定时伸缩的功能。知乎在这一块二次开发Cluster Autoscaler组件,以及自研了ClusterCronHPA组件,实现定时伸缩功能。动态节点调度在理想情况下是可以解决成本的,但是也不要过于理想。比如知乎就没有使用调度伸缩做成本管控,因为按照小时计算成本基本上就是物理机的1.5倍,这一块要看云厂商或者是机房能够谈下合理成本的情况下使用合适。不然就只能当做稳定性应急工作使用,当然CA也可以有一些其他用途。例如改造过的原生CA组件,不只是可以弹扩k8s集群内资源,也可以弹集群外资源,如果基础类组件或存储服务兵不在K8s内的。可以集成K8s外节点资源给基础组件,或者是存储类服务做弹性应用。
再离线混部
在企业的IT环境中,通常运行俩大类进程。一类是在线服务应用,另一类是离线作业。在离线混部,顾名思义就是把
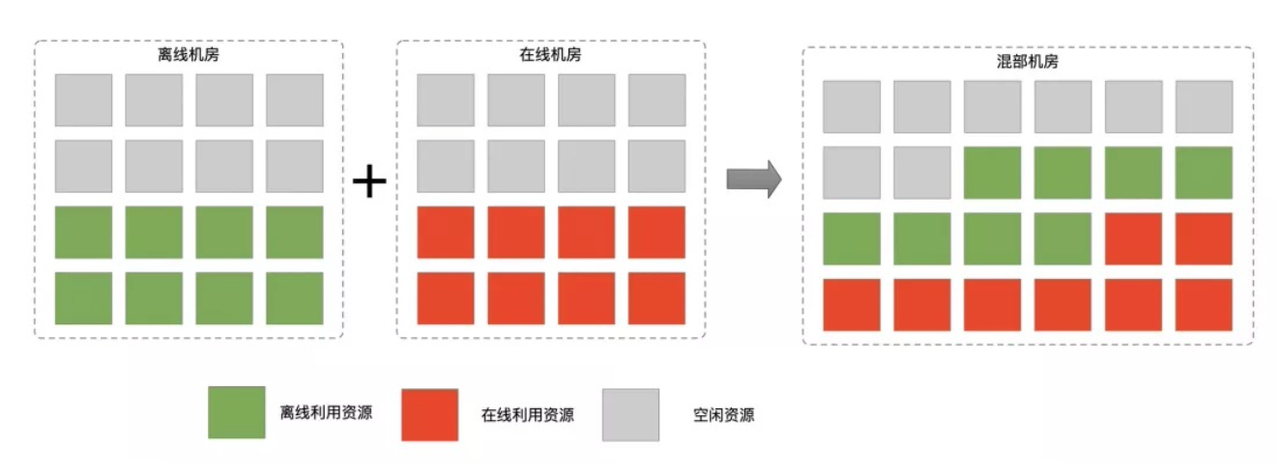
在企业的IT环境中,通常运行两大类进程。一类是在线服务应用,另外一类是离线作业。在离线混部,顾名思义就是把在线应用和离线作业混在一起跑。 在线应用在运行时间,服务流量及资源利用率具有潮汐特征,以及时延敏感,并且对服务对SLA要求极高。 然而离线作业,在运行时间分区间,运行过程中利用率较高。到那时时延不是太敏感,容错率高一些。中断后一般允许重运行,如Hadoop 生态下的MapReduce,Spark作业等。 因为在线资源利用率有明显的起伏特征,所以一些混部场景主要通过填充离线作业的弥补在线空闲资源时间段的空缺。从而提升资源利用率。空闲阶段的资源可以减少企业的一部分开支,合理利用可以减少企业对物理服务器的采买,甚至可以减少部分节点。
关键技术
知乎是2022年9月份着手搞在离线混部,早期时候接触过阿里云、腾讯云、华为云、百度云以及一些商业公司的产品。由于一些产品对业务有侵入性,以及一些产品对业务改造成本过高。在这个情况下,考虑人员成本和接入成本,为了更务实,知乎选择了自主研发。
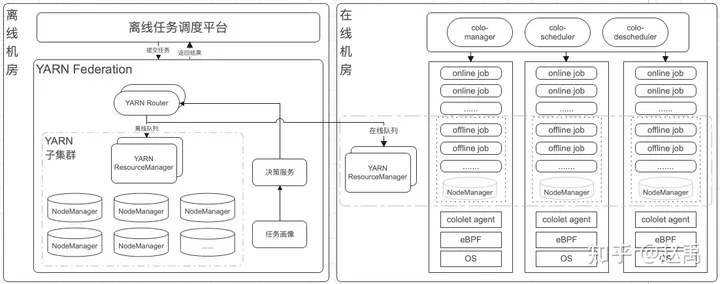
通过图4-1所示,来看一下在离线混部架构图。知乎在线和离线是在不同的机房,知乎的离线主要使用YARN进行资源调度。通过架构图可以得知在线和离线使用的单独的调度器,是分开调度的。在线部分与离线部分结合主要通过NodeManager进行离线任务调度, 下面来详细介绍一下在离线混部的关键技术。
再离线调度介绍
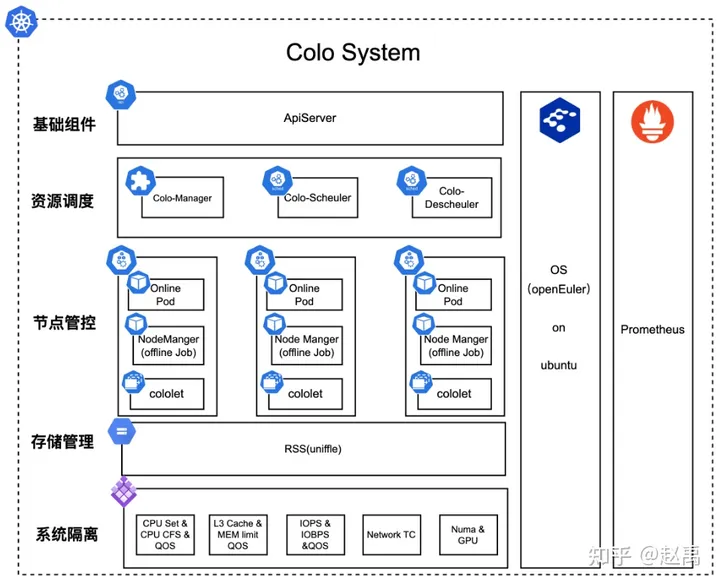
通过图4-2来看一下colo调度器的系统架构,目前colo支持k8s 1.16.x 以上版本。 colo 主要分为5层,分别为:
- 基础组件: 主要调用k8s ApiServer 进行k8s资源交互。
- 资源调度: 资源调度层主要负责资源调度和资源同步及计算。
- colo-manager:负责node节点cololet agent配置同步,例如BE内存&CPU分配比例, 开启某项压制开关等、其次就是Node resource 计算工作。
- colo-scheduler: 负责在线和离线应用调度, 扩展了负载均衡调度(包含CPU、Memory、CPI干扰)、重调度预调度(重调度驱逐时的安全策略)、ColocationFit 插件。
- colo-descheuler: 重调度器,扩展了负载均衡调度插件。主要应用于实时运行过程中,二次调度pod。扩展了高级防护策略,按照Node、Namespace、Workload进行保护。
- 节点管控:节点管控层主要是节点级调度器和离线应用调度器。
- NodeManager: 是Yarn中单节点的代理,它管理Hadoop集群中单个计算节点,其需要与应用程序的ApplicationMaster和集群资源管理器RM交互。
- cololet: 节点级调度器、主要负责CPI(Cycle Per Instruction)、LC(Latency Critical) 动态指标采集、OS QOS分级、资源隔离、过载保护、full-pcpus-only绑核等。
- 存储管理:由于离线模型数据在离线机房,这一块知乎读取数据模型采取了存算分离,通过uniffle读取shuffle数据。在使用uniffle过程中,我也多次给uniffle提交了PR。
- 系统隔离: 系统隔离层,知乎的系统主要使用openEuler、但是由于知乎的在线系统内核是Ubuntu属于Debian生态的资源,所以这一块知乎自编译了openEuler内核到Ubuntu。系统隔离层,主要是利用openEuler的cgroup管理,对CPU、Memory、IO、网络、Numa、GPU、OS QOS 管理。
核心技术介绍
资源隔离是为了保障在线应用服务稳定性,并且压制一些离线的资源使用。在内核部分,知乎都是采用openEuler on Ubuntu,利用了一些openEuler的QOS机制。
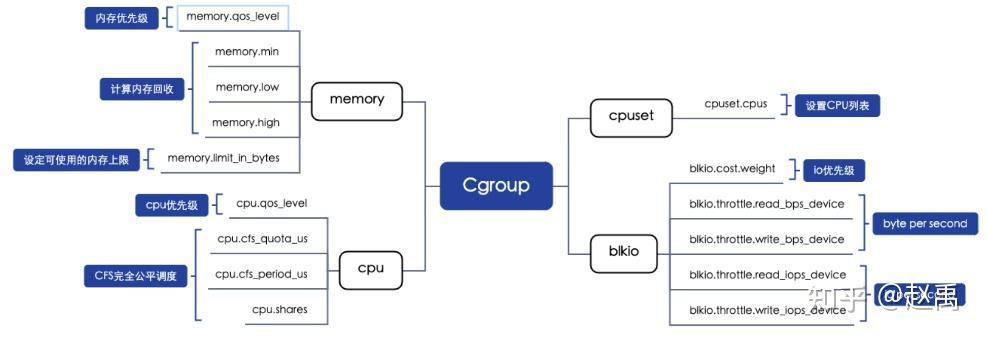
这些Cgroup子系统接口是colo调度器主要使用的。
cpu、内存、IO优先级
CPU优先级配置,针对在离线业务混合部署的场景,确保在线业务相对离线业务的CPU资源抢占。 CPU优先级内核接口,/sys/fs/cgroup/cpu目录下容器的Cgroup中,如/sys/fs/cgroup/cpu/kubepods/besteffort/<PodUID>/<container-longid>目录cpu.qos_level接口开启CPU优先级配置,默认值为0, 有效值为0和-1。0标识为在线业务、-1标识为离线业务。然而colo会对pod进行判断、判断pod的annotations标签 colo.sh/offline 等于 true时自动设置对应的besteffort类型pod。离线任务知乎都是按照k8s QOS besteffort 进行设定。 内存优先级配置,针对在离线业务混合部署的场景,确保OOM时优先kill离线业务。内核支持针对Cgroup的memory优先级配置,memory子系统存在接口memory.qos_level,但是要开启优先级支持需要打开“echo 1 > /proc/sys/vm/memcg_qos_enable” 配置。memcg_qos_enable配置默认值为0,有效值为0和1。0表示关闭特性、 1表示开启特性。memory.qos_level接口配置,默认值为0,有效值为0和-1。0标识为在线业务,-1标识为离线业务。 其次就是IO优先级配置,是利用cgroup的blkio子系统的blkio.cost.weight接口进行设定。
CPU隔离 CPU的隔离压制策略主要是两种:一种是cpuset,另外一种是cfsQuota。两者的区别在于,cpuset是占用整数的核心数,而cfsQuota会更精细一些,利用Linux CFS完全公平调度,根据进程优先级 ∕ 权重或控制组分配CPU使用的调度程序,在控制组间按比例分配 CPU时间(CPU 带宽)。
- cpuset可以通过Cgroup子系统cpuset/下cpuset.cpus进行调节CPU列表,需要注意的是子集不能超过跟级的设定范围,不然设定会不成功, 也设定不了。
- cfsQuota可以通过Cgroup子系统子集cpu/下的cpu.cfs_quota_us与cpu.cfs_period_us,cpu.shares进行设定。cpu.cfs_quota_us与cpu.cfs_period_us这两个接口表示在period时间周期内的CPU带宽限制(能够使用CPU的时间),单位是微妙,例如当period参数设置为1秒,将quota参数设置为 0.5 秒,那么Cgroup中的进程在1秒内最多只能运行 0.5 秒,然后就会被强制睡眠,直到进入下一个1秒才能继续运行。然而cpu.shares参数,设置控制组中CPU可用时间的相对比例。
内存回收 内存回收目前支持多种内存策略。针对不同场景使用不同的内存分配方案,以解决多场景内存分配。
- dynlevel策略:基于内核Cgroup的多级别控制。通过监测节点内存压力,多级别动态调整离线业务的memory Cgroup,尽可能地保障在线业务服务质量。
- fssr策略:基于内核Cgroup的动态水位线控制。memory.high是内核提供的memcg级的水位线接口,colo动态检测内存压力,动态调整离线应用的memory.high上限,实现对离线业务的内存压制,保障在线业务的服务质量。
memory dynlevel策略内核接口,/sys/fs/cgroup/memory目录下容器的cgroup中,如/sys/fs/cgroup/memory/kubepods/burstable/<PodUID>/<container-longid>目录。dynlevel策略会依据当前节点的内存压力大小,依次调整节点离线应用容器的下列值:
- memory.soft_limit_in_bytes
- memory.force_empty
- memory.limit_in_bytes
- /proc/sys/vm/drop_caches
memory fssr快压制慢恢复策略,策略内核接口/sys/fs/cgroup/memory目录下容器的Cgroup中,如/sys/fs/cgroup/memory/kubepods/burstable/<PodUID>/<container-longid>目录。fssr策略会依据当前节点的内存压力大小,依次调整节点离线应用容器的下列值:
- memory.high
- memory.high_async_ratio
fssr的策略如下:
- cololet启动时,默认配置所有离线的memory.high为总内存的80%。
- 当内存压力增加,可用内存freeMemory < reservedMemory(预留内存,totalMemory 5%) 时认为内存紧张,此时压缩所有离线的memory.high, 压缩量为总内存的10%,即最新的memory.high=memory.high-totalMemory 10%。
- 当持续一段时间总内存比较富裕,即可用内存freeMemory > 3 reservedMemory(totalMemory 5%)时认为内存富裕,此时释放总内存的1%给离线应用,memory.high=memory.high+totalMemory 1%, 直到memory free 介于reservedMemory与3 reservedMemory之间。
网络隔离 网络隔离技术要根据k8s集群网络插件和网络模型选择,有很多方式,不过一些复杂的网络环境还需要直接写ko驱动通过patch形式隔离。而知乎的主要是Calico和Flannel两种。这一块知乎的网络隔离主要是使用bpftrace + tc做的。通过bpftrace采集流量指标,做流量测算。通过modprobe、ip link、tc qdisc 等命令建立虚拟网卡设备,通过tc qdisc建立ingress与egress,从而限制上行流量和下行流量。如果pod的Annotation标签带有 colo.sh/offline 等于true指定该设备。
离线调度结合
在使用NodeManager对YARN Federation任务进行调度时,知乎使用的hadoop版本是v3.2.1。调用YARN Federation多个集群配置不一致会存在一些bug,这一块我们进行了改造。并且通过cololet agent提供资源利用接口数据,NodeManager对cololet接口获取节点资源进行任务下发和任务画像工作。

混部的每台机器提供给NodeManager使用的资源是实时计算的、如图4-4所示。每个节点能够提供给NodeManager使用的资源是根据每台机器实时负载通过cololet计算所得,计算可以给BE任务预留的资源。然后NodeManager读取cololet提供的接口获取实时分配资源,上报给ResourceManager进行离线任务分配调度。这样可以时时调整可分配资源,低峰时多分配些,高峰时少分配些。
问题解决
在开发colo与离线任务调度和生产部署时遇到过很多问题,针对这一块做一些总结,列举一部分。主要分为几大类:调度类、单机隔离类、离线部署类、存储类、迁移类问题。
调度器类问题
- 在开发调度器时,起初均衡调度是使用指标metrics-server进行,但是发现指标采集粒度和周期比较长,指标采集周期是30s。然后就放弃了使用metrics-server,改用cadvisor结合crd(nodemetrics)资源存储。scheduler framework的plugin读取crd(nodemetrics)资源进行打分和过滤测算。
- cadvisor主要获取的是pod的指标和node本身实际使用不匹配。所以要保证实际意义上的均衡,还要考虑node指标。
- 知乎k8s集群跨度比较大,v1.16.x、v1.17.x、v1.19.x、v1.2x.x集群都有,所以在做调度器时,需要兼容多个版本。
单机隔离类问题
- 在k8s使用Node Manager时,Node Manager是有自己的Cgroup管理机制,Node Manager的Cgroup需要关闭。不然会不受pod 的Cgroup限制。
- 在k8s使用Node Manager时,知乎是通过DaemonSet进行部署。虽然colo调度器对pod 本身request&limit配置进行扩展,从而实现资源隔离,并以 QOS besteffort进行分配。但是带来一个问题资源是固定的,不能足够的使用node资源,要保证这种情况就要拿到空闲资源对离线任务资源quota进行设定。这一块colo是按照空闲资源的80%进行设定。
- 版本小于kubernetes 1.22版本的集群开启了single-numa-node和绑核,intel下不是固定绑核。最终colo支持full-pcpus-only解决。
离线部署类问题
- NodeManager 在k8s部署时,调用java部分的进程,都习惯用shell脚本进行。但是通过shell调度的进程在k8s内使用需要有trap进行信号传递,不然会导致信号丢失。容易造成僵尸进程和孤儿进程。
- 过载保护策略使用,本身cololet是支持一些过载保护策略。例如cpu evict和memory evict。是为了兼容spark submit这种形式的job,但是没有开启。因为通过DaemonSet运行NodeManager,去开启cololet agent的过载保护策略就没有意义。
存储类问题
- 由于在线机器的磁盘过小, shuffle 过程有对磁盘存在大量数据读写。所以采用了存算分离进行,这一块知乎采用了uniffle。uniffle的k8s operator并不是太成熟。例如调整shuffle-server和coordinator的端口,以及toleration和nodeSelector都是不支持的,所以我们给官方提了PR。
- 起初shuffle-server是采用StatefulSet部署,后发现shuffle-server一些机器使用资源过低。一个node节点部署4个shuffle-server。
收益
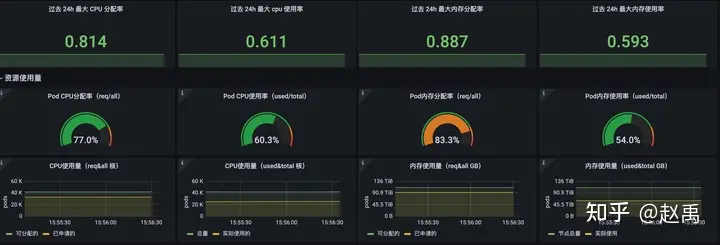
从2月上线生产后,截至目前在离线混部上线的节点2k+台node节点。上混部调度器的多个集群全天利用率均值40+%以上,白天实时利用率在50% ~ 65%之间,如图4-5所示。
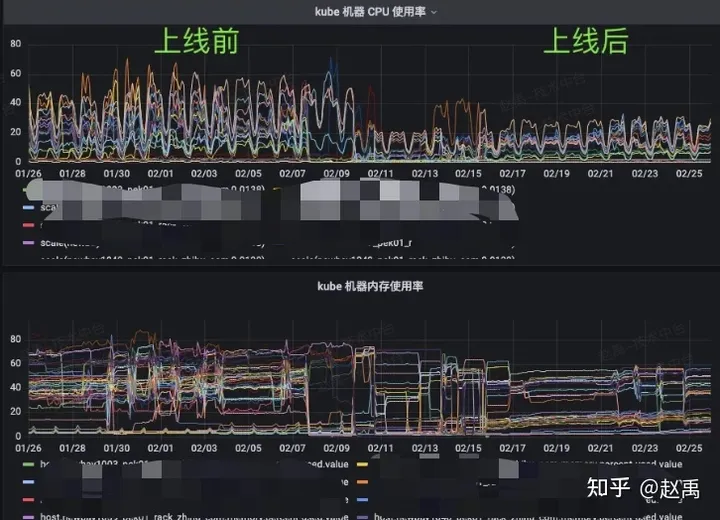
上线混部调度器后,服务均衡也得到了改善,如图4-6所示。
总结
在离线混部这件事情上,要结合自身的场景去判断收益,开展工作。例如知乎而言,如果是要下机器的话,不是特别现实。因为本身知乎的机器整体的服务在资源使用上利用率就偏高。只能说通过提升利用率释放空闲资源,减少对服务器的采买。对这件事情而言,其实除了资源的收益,对业务的精细化调度也是有一定收益的,精细化调度可以提升服务的稳定性,更合理地应用资源。避免应用与应用之间的干扰。
此过程中,知乎离线团队也在项目中完成大量工作,比如: Shuffle数据读写优化、
One comment
请问你们的组件有开源吗