分布式事务
现在分布式事务成了主流,但使用分布式也随之带来了一些问题和痛点,分布式事务就是最常见的问题
俩阶段提交方案/XA方案
俩阶段提交方,有一个事务管理器的概念,负责协同多个数据库的事务,事务管理器先问各个数据库准备好了吗,如果每个数据库都回复ok,那么就正式提交事务,在各个数据库上执行操作了如果任何一个数据库回答不ok,那么就回滚事务.
这种分布式事务方案,比较适合单块应用里,跨多个库的分布式事务,而全英文引种依赖数据库层面来搞定复杂的事务,效率很低,绝对不饸高并发的场景.如果要用spring+JTA就可以搞定
这个方案很少用,一般来说某个系统内部如果出现跨多个库的这么一个操作,是不合规的.
- 第一阶段:协调者想参与者发起指令,参与者评估自己的状态,如果参与评估者与指令可以完成,则会写redo或undo日志,然后锁定资源,执行操作,但并不提交
- 第二阶段:如果没个参与者明确准备成功,则邪恶跳着向参与者发送提交指令,参与者释放锁定的资源,如果任何一个参与者明确返回准备失败,啧协调者发送终止指令,参与者取消已经变更的事务,释放锁定资源
两阶段提交方案应用非常广泛,几乎所有商业OLTP数据库都支持XA协议。但是两阶段提交方案锁定资源时间长,对性能影响很大,基本不适合解决微服务事务问题。
二段提交的缺点
- 同步阻塞问题.执行过程中,所有参与节点都是阻塞型的.当参与者占有公共资源,其他第三方节点访问公共资源不得不处于阻塞状态
- 单点故障.由于协调者的重要性.一旦协调者发生故障.参与者会一直阻塞下去.尤其是在第二阶段,协调者发生故障,那么所有的参与者还处于事务资源锁定的状态中,无法继续完成事务操作(协调者挂掉,可以重新选一个协调者,但无法解决因为协调者宕机导致的参与者处于阻塞状态的问题)
- 数据不一致.在第二阶段提交的阶段二中,当协调者想参与者发送commit请求之后,发生了局部网络异常或者在发送commit请求中协调者发生了故障,这会导致只有一部分参与者接收到了commit请求.而在这部分参与者街道commit请求之后机就会执行commit操作.但是其他未接收到commit请求的机器无法提交.于是整个分布式系统便出现了数据不一致的现象
- 二阶无法解决的问题:协调者发出commit消息之后宕机,而为一接收到这条消息的参与者同时也宕机了.那么及时协调者通过 选举产生了新的协调者,这条事务状态也是不确定的,没人知道是否已被提交
传统模式JTA+Atomokos
出台弄项目中,比如项目中用到了多数据源的时候,大多数采用jta+atomikos分布式事物问题,jta+Atomickos底层是基于XA协议的俩段提交方案
XA协议:XA事物的基础是俩阶段提交协议.需要有一个事物协调者来保证所有的事务参与者都完成了准备工作(第一阶段).如果协调者收到参与者都准备好的消息,就会通知所有的事务都可以提交了(第二阶段)mysql在这个XA事务中扮演的是参与者的角色,而不是协调者(事务管理器)
JTA:java Transation API 是javaEE13个开发规范之一.java事务api,运行应用程序执行分布式事务处理.在俩个或者多个网络计算机资源上访问并且更新数据.JDBC驱动程序的JTA支持极大的增强了数据访问能力.事务最简单最直接的就是保证数据的有效性,和数据的一致性
Atomockos:Atomikos TransactionEssentials是一个为java平台提供增值服务的开源类事务管理器
2pc与3pc的实现与区别
增加了 一个询问阶段,询问阶段开源确保尽可能的发现无法执行而需要终止的行为,但是谈发现所有这种行为,只会减少这种情况的发生在准备阶段以后,协调者和参与者执行的任务中都加了超时,一旦超时,协调者和参与者都继续提交事务,默认为成功,这也是根据概率上超时后默认最成功的正确性最大.
与俩段提交不同的是,三段提交有俩个改动点
- 引入超时机制.同时在协调者和参与者中都引入超时机制
- 在第一阶段和第二个阶段中插入一个准备阶段,保证了在最后提交阶段之前各参与节点的状态也是一致的
详解三段提交协议
canCommit阶段:
- 协调者向参与者发送canCommit请求.询问是否可以执行事务提交操作.然后开始等待参与者的回应
- 想要反馈 参与者接到CanCommit请求之后,正常情况下,如果其自身认为可以顺利执行事务,则返回yes想要,并进入预备状态.否则返回No
preCommit阶段
- 发送预提交请求, 协调者想参与者发送PreCommit请求,并进入Prepared阶段
- 事务预提交 参与者接收到了PreCommit请求后,会执行事务操作,并将undo和redo信息记录到事务日志中
- 响应反馈 如果参与者成功的执行了事务操作,啧返回ACK响应,同时开始等待最终命令
假如有任何一个参与者想协调者发送了No响应,或者等待超时之后,协调者都没有接到参与者的响应,那么就执行事务的中断
- 发送中断请求 协调者向所有参与者发送abort请求
- 中断事务参与者受到来自协调者的abort请求之后,执行事务中断
DoCommit阶段
该阶段进行真正的事务提交
执行提交
- 发送提交请求,协调接收到参与者发送的ACK响应,那么他将从预提交状态进入到提交状态.并行所有参与者发送doCommit请求
- 事务提交 参与者接收到的doCommit请求之后,执行正式的事务提交.并在完成事务提交之后释放所有事务资源.
- 响应反馈 事务提交完成之后,向协调者发送Ack响应
- 完成事务 协调者接收到所有参与者的ack响应之后完成事务
相对于2pc,3pc主要解决单点故障的问题, 并且减少阻塞,因为一旦参与者无法及时收到来自协调者的信息后,他会默认执行commit.而不是一直持有事务资源并处于阻塞状态.但是这种机制也会导致数据一致性的问题,因为,由于网络原因,协调者发送的abort响应没有几十倍参与者接收到,那么参与者在等待超时之后执行了commit操作.这样就和其他接收到abort命令并执行回滚的参与者之间存在数据不一致的情况.
TCC补偿性方案
什么是TCC

TCC分别对应Try,Confirm,Canel具体含义如下
- Try:预留业务资源
- Confirm:确认执行业务操作
- Cancel:取消执行业务操作
讲TCC三个操作与关系型数据库的事务操作想比,有异曲同工之妙
TCC型事务
一般满足acid的事务为刚性事务,满足base理论的为柔性事务
TCC属于补偿型柔性事务,本质也是一个俩阶段型事务,这是与JTA纪委相似的,但是与JTA不同的是,JTA属于资源层事务,而TCC是服务层事务
在一个长事务中,一个有俩台服务器一起参与的事务,A发起事务,b参与事务,B的参与事务需要人工参与,所以处理时间可能很长.如果按照ACID原则,要保持事务的隔离性,一致性,服务A中发起的事务资源将会被锁定,不允许其他应用访问到事务过程的中介见过,知道整个事务被提交或者回滚.这就造成事务A中的资源被长时间锁定,系统的可用性将不可接受.
WsBusinessActivity提供了一种基于补偿的long-running的事务处理模型..还是上面的例子,服务器A的事务顺利执行,那么A就先行提交,如果事务B也提交,整个事务就算已完成.但是如果事务B执行失败,事务B本身回滚,这是A被提交,所以需要一个补偿型操作,讲已提交的事务A执行的操作做反操作,回复到未执行事务A的状态.这样的SAGA事务模型,是牺牲了一定的隔离性和一致性的,但是提高了long-running事务的可用性
在JTA事务中,所有需要被事务管理的资源 都需实现指定接口,同理TCC事务的服务也必须提供相应的接口实现.在RCC中这些接口为try,confirm,canncel缩写为TCC. TCC事务管理器会使用这些接口协调多个服务
Try尝试执行业务
- 完成所有业务检查(一致性)
- 预留必须业务资源(准隔离性)
Confirm:确认执行业务
- 真正执行业务
- 不做任何业务检查
- 只是用Try阶段预留的业务资源
- Confirm需要能满足幂等性
Cancel:取消执行业务
- 释放Try阶段预留的业务资源
- Cancel操作需要满足幂等性
TCC与2PC协议比较
- 位于业务服务层而非资源层
- 没有单独猪准备Prepare阶段,Try操作兼具备操作与准备能力
- Try操作可以灵活选择业务资源的锁定力度
- 较高开发成本
TCC设计
一个好的TCC框架至少满足一下特点
- 不予特定的框架耦合,
- 提供基于注解的配置而不是xml服务的配置方式
@Compensable(confirmMethod = "confirmRecord", cancelMethod = "cancelRecord",transactionContextEditor = DubboTransactionContextEditor.class)
@Transactional
public String record(CapitalTradeOrderDto tradeOrderDto) {
return "success";
}
@Transactional
public void confirmRecord(CapitalTradeOrderDto tradeOrderDto) {
}
@Transactional
public void cancelRecord(CapitalTradeOrderDto tradeOrderDto) {
}- 支持多种事务日志持久化机制:事务日志持久化的性能是影响TCC性能的一个很重要因素,因此支持多种持久化机制便于根据特定应用场景进行灵活选择,比如支持基于文件、基于redis(开启AOF)、基于zookeeper、基于mysql等等。使用何种持久化机制,框架应该支持在xml或者注解中进行配置。
- 支持可配置recovery策略:对于异常的事务(比如Confirm失败),TCC框架应该提供recovery机制,它会对事务日志进行扫描监控,并根据策略进行recovery操作。策略必须是可以配置的(基于xml或者注解),配置项可以有:最大重试次数、recovery时间间隔、支持Cron表达式等。
- 使用spring:由于spring框架几乎存在于每一个java项目中,因此TCC框架有理由选择spring来进行:依赖注入、aop、spring声明式事务等。
消息队列实现分布式事务
RocketMQ
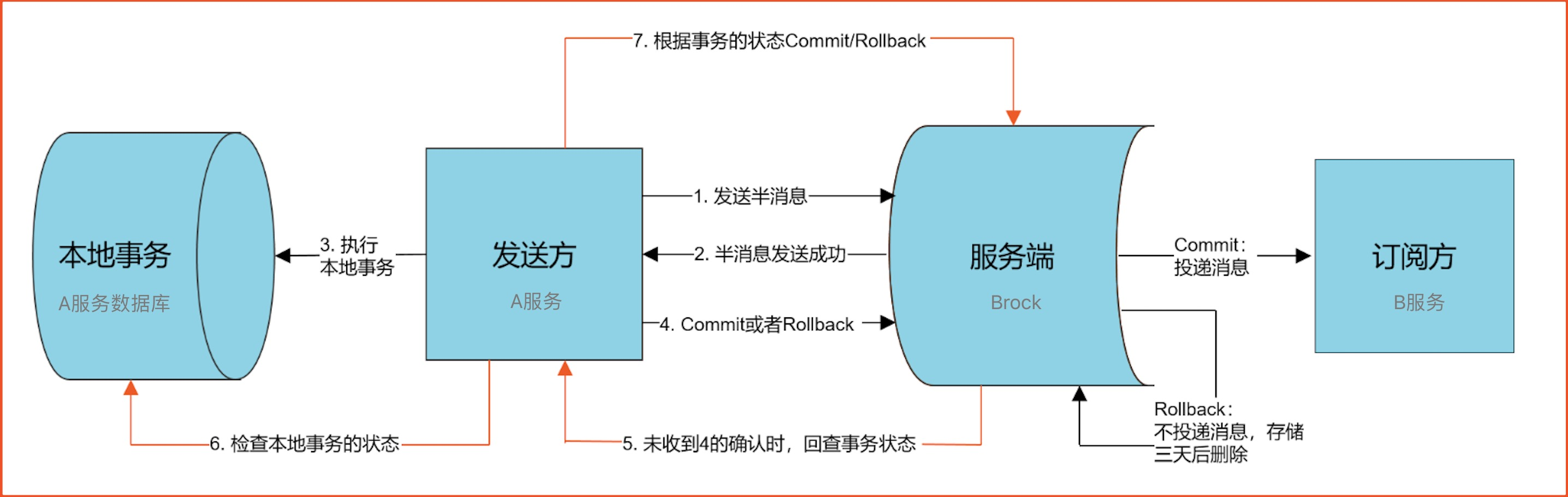
- 在消息队列上开启一个事务主题
- 事务中第一个执行的服务发送一条半消息(半消息和普通消息的唯一区别是,在事务提交之前,对于消费者来说这个消息是不可见的)给消息队列
- 办消息发送成功后,发送办消息的服务就会开始执行本地事务根据本地事务执行结果来决定事务消息提交后者回滚,RocketMQ提供食物反查来解决异常情况.如果RocketMQ没有提交或者回滚的请求,Broker会定时生产者上去反查本地事务的状态,然后根据生产者本地事务的状态来处理这个"半消息"是提交还是回滚.值得注意的是我们需要根据自己的业务逻辑来实现反查逻辑接口,然后根据返回值Broken自己做提交或者回滚,这个反查接口已经做到了无状态的,请求到任意一个生产者节点都会返回正确数据
- 本第十五成功后会让这个"半消息变成正常消息",提供分布式事务后面的步骤执行自己本地事务.(这里的事务消息,producer不会有我consumer消费失败而做回滚,采用事务消息的应用,其所追求的是高可用性和最终一致性,消息消费失败的话,MQ自己会负责重推消息,知道消费成功.当然可以根据自己业务来反向操作)
Q:如果当前使用的消息队列不支持"办消息/预发消息"怎么做
A:可以使用关系型数据库的一行记录来记录本地事务,使用状态列表来表示本地事务的执行解雇,通过异步线程不断捞出本地事务执行成功的消息发生到MQ中
Q:为什么要增加一个消息预发送机制,增加俩次发布出去的消息重试机制,为什么不在业务成功之后,发送一次失败的话使用一次重试机制?
A:如果业务执行成功,再去发送消息,此时如果还没来得及发消息,业务系统就已经宕机了,系统重启后,根本没有记录之前是否发送过消息,止痒就会导致业务执行成功,消息最终没法发出去的情况.
Q:如果consumer端业务业务异常而导致回滚,那么岂不是无法保证一致性
A:我们上面提到过在分布式十五中只允许系统异常失败.我们可以通过重试来实现最终一致性,或通过监控差错系统来单独处理这类问题.俩阶段提交方式不适合强一致性的业务场景