K8s学习笔记
云原生
云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式APl云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用.云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式APL
这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统作出频繁和可预测的重大变更。这些技术能够构建容错性好、易于管理和便于观察的松耦合系统.结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统作出频繁和可预测的重大变更.
springcloud和kubernetes有很多功能是重合的
- 服务注册发现
- API网关
- 负载均衡
- 配置管理
简介
一个k8s集群包括控制平面(control plane),以及一个活多个工作节点(work node)
控制平面(Control Plane):控制平面负责管理给自己点和维护集群状态.所有任务分配都来自于控制平面
工作节点(Worker node):工作节点负责执行由控制平面分配的请求任务,运行实际的应用和负载
kube-api
如果需要与k8s集群进行交互,就要通过API
apiserver是kubernetes控制平面的前端,英语处理内部和外部请求
kube-scheduler
集群状态是否良好?如果需要创新的容器,要将它们放在哪里?这些是调度程序需要关注的问题
scheduler调度程序会考虑容器集的资源需求(例如CPU或者内存)以及集群的运行状态.随后,它会将容器安排到适当的计算节点
etcd
键值对数据库,用于存储配置数据和集群状态信息.
kube-controller-manager
控制器负责实际运行集群,controller-manager控制器管理器则是将多个控制器功能合一,降低了程序的复杂性
- 节点控制器:负责节点出故障时进行通知和响应
- 任务控制器:检测代表一次性任务的job对象,然后创建pods来运行这些任务直至完成
- 端点控制器:填充端点(endpoints)对象(即加入Service与pod)
- 服务账户和令牌控制器:为新的命名空间创建默认账户和API访问令牌
node
节点组件会在每个节点上运行,负责维护运行的pod并提供kubernetes运行环境
kubelet
kubelet会在急群众每个节点(node)上运行.它保证容器(containers)都运行在pod中
当控制平面需要再节点中执行某个操作时,kubelet就会执行该操作
kube-proxy
kube-proxy是集群中每个节点节点node上运行的网络代理,是实现kubernetes服务(Service)概念的一部分
kube-proxy维护节点网络规则和转发流量,实现从集群内部或外部的网络与Pod进行网络通讯
container runtime
容器运行时是负责运行容器的软件
cloud-controller-manager
控制平面还包含一个可选组件cloud-controller-manager
云控制器管理器,允许你将你的集群连接到云提供商的API之上,并将与该云平台的集群交互的组件分离开来
如果在自己的环境中运行K8s或者在本地计算机中运行学习环境,所部署的集群不需要有云控制管理器
K3s
K3s是一个轻量级,完全兼容的Kubernetes发行版本.非常适合初学者.
K3s将所有K8s控制平面组件都封装单个二进制文件和进程中,文件大小<100MB,占用资源更小,而且包含了Kubernetes运行需要的部分外部依赖和本地存储提供的程序.
K3S集群分为K3s server(控制平面)和k3s Agent工作节点.所有的组件都打包在单个二进制文件中.
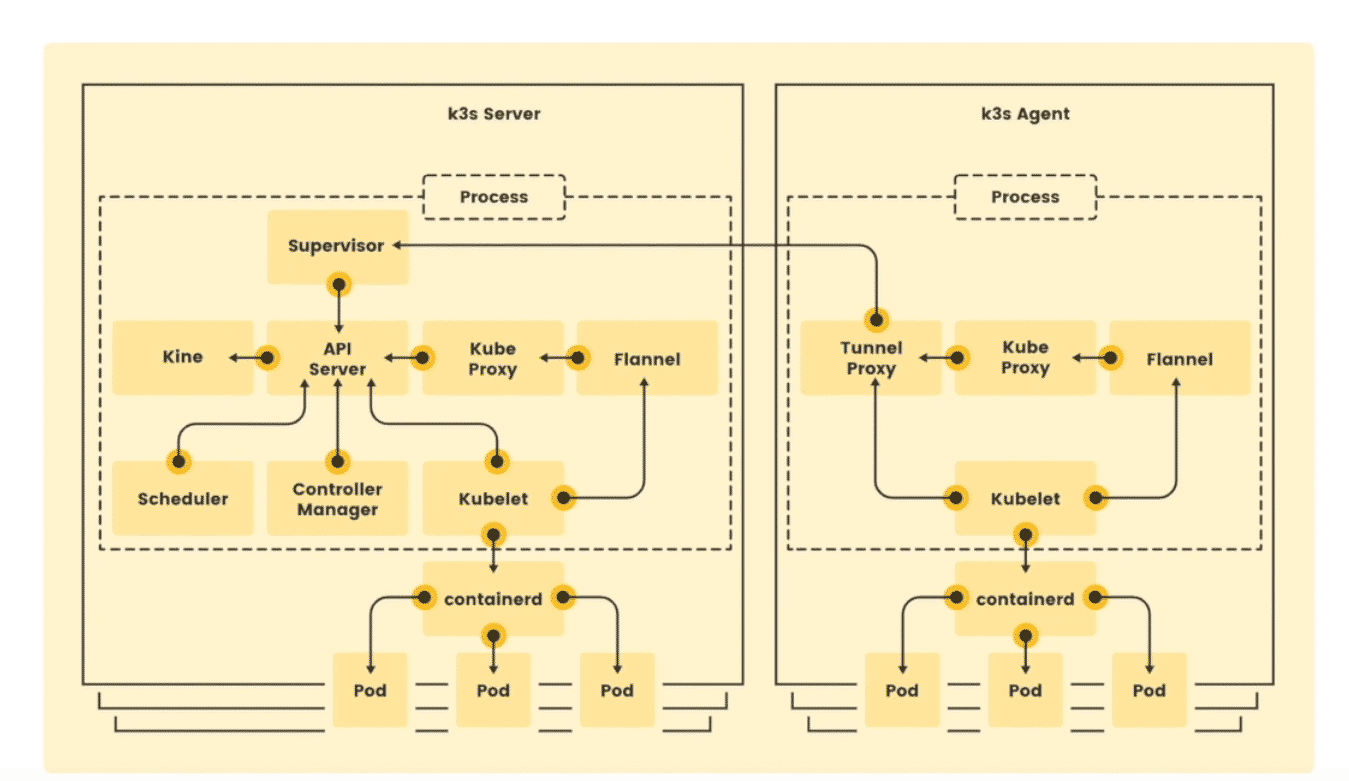
最低内存512G,cpu1核心
deployment
是对replicaset和pod更高级的抽象
它使Pod拥有多副本,自愈,扩缩容,滚动升级等能力
Replicaset是pod的集合
它可以设置运行pod的数量,确保任何时间都有制定数量的pod副本在运行.
通常我们不直接使用replicaset,而是在deployment中声明
#创建deployment 设置3个副本(小于3会自动创建)
kubectl create deployment nginx-deploy --image=nginx:1.22 --replicas=3
#查看deploy
kubectl get deploy
#查看pod
kubectl get pod
#查看replicaSet
kubectl get replicaset
#持续观察副本数量
kubectl get replicaset --watch
#设置为5个deployment
kubectl scale deployment nginx-deploy --replicas=5
#自动缩放
kubectl autoscale deployment/nginx-auto --min=3 --max=10 --cpu-percent=75
#升级版本(自动滚动发布)
kubectl set image deploy/nginx-deploy nginx=nginx:1.23
# 查看部署的版本 --revision=1
kubectl rollout history deploy/nginx-deploy
#回滚到第一个版本(回滚也是操作副本集进行的回滚)
kubectl rollout undo deploy/nginx-deploy -to-revision=1
#查看副本集
kubectl get rs自动缩放
自动缩放通过增加和减少副本数量,以保持所有pod平均CPU利用率不超过75%
自动伸缩需要声明pod的资源限制,同时使用metrics server(k3s默认已安装)
service
servece将运行在一组pods上的应用程序公开为网络服务的抽象方法.
service为一组Pod提供相同 DNS,并且在它们之间进行均衡负载
k8s为pod提供分配了IP地址,但IP地址可能会发生变化
集群内部的容器可以通过Service名称访问服务,而不需要担心pod的IP发生变化
k8sService定义了这样一种抽象
逻辑上的一组可以相互替换的Pod,通常称为微服务,Service对应Pod集合通常是通过选择算符来确定的
比如在SErvice中运行了3个nginx副本.这些副本是可以互换的,我们不需要关心它们调用了哪个Nginx,也不需要关注Pod的状态,只需要调用这个服务既可以了
# 查看所有服务器 service
kubectl get all
# 将deploy暴露为service --name后面是服务对外暴露出去的名称
kubectl expose deploy/nginx-deploy --name=nginx-service --port=8080 --target-port=80
#
# 获取服务信息
kubectl get service输出
root@k8s-master:/home/nsyl# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.43.0.1 <none> 443/TCP 23h
nginx-service ClusterIP 10.43.126.226 <none> 8080/TCP 2m41s访问
10.43.126.226:8080
#查看service 可以看到有多个端点
kubectl describe service nginx
#进入pod退出pod自动删除
kubectl run test -it --image=nginx:1.23 --rm -- bash
# 进入pod,可以根据kubectl get pod进入
kubectl exec -it [服务名] -- bashServiceType取值
ClusterIP:将服务公开在集群内部.k8s会给服务分配一个集群内部的IP,集群内的所有主机都可以通过Cluster-Ip访问服务.集群内部的Pod可以通过service名称访问服务.
NodePort:通过每个节点的主机IP和静态端口NodePort暴露服务.集群外的主机可以使用节点IP和NodePort访问服务
ExternalName将集群外部的网络引入集群内部
LoadBalancer:使用云提供商的负载均衡器向外部暴露服务
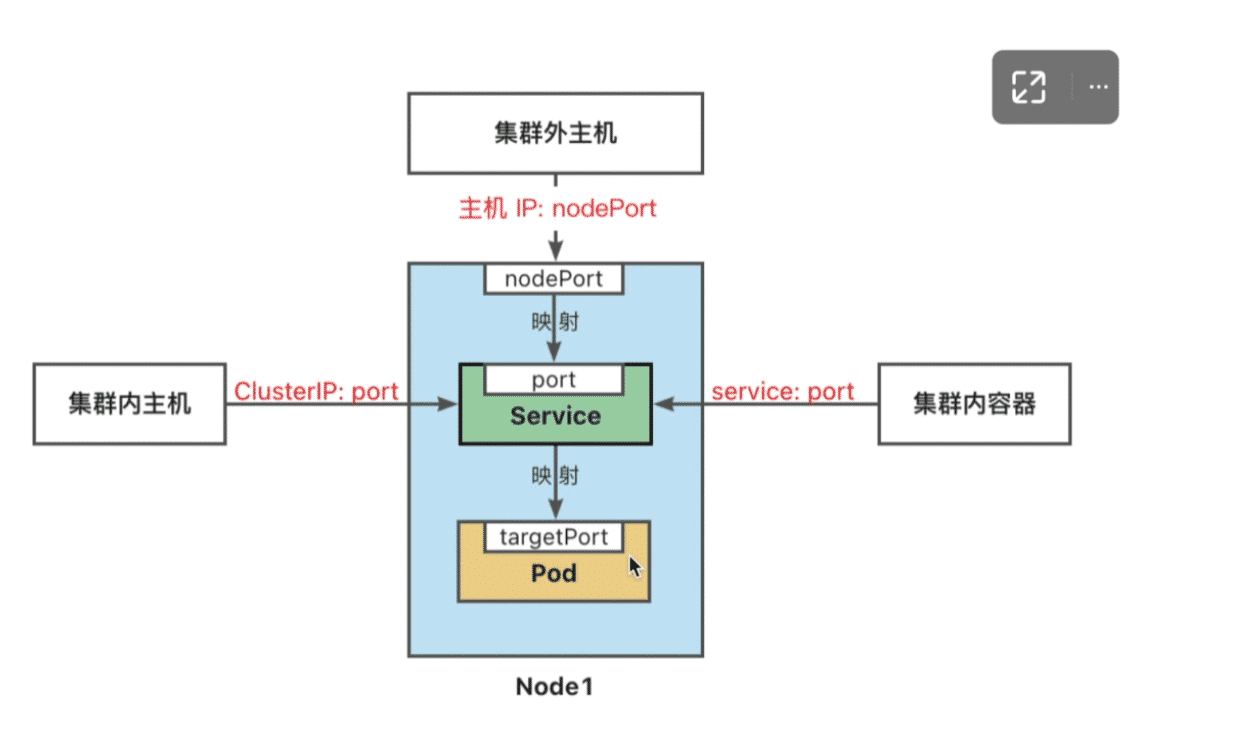
命名空间
namespace是一种资源隔离机制,将同一集群中的资源划分为相互隔离的组.命名空间可以在多个用户之间划分集群资源(通过资源配额)
例如我们可以设置开发,测试,生产,等多个命名空间
同一个命名空间的资源名称要唯一,但跨命名空间没有这个要求.
命名空间作用域进针对带有名字空间的对象,例如deployment,service
这种作用域对集群访问的对象不适用,例如storageClass(存储类),Node(节点),PersistentVolume(存储卷)等
这是默认k8s的命名空间
root@k8s-master:/home/nsyl# kubectl get namespace
NAME STATUS AGE
default Active 24h
kube-system Active 24h
kube-public Active 24h
kube-node-lease Active 24hKubernetes会创建四个初始命名空间:
default默认的命名空间,不可删除,未指定命名空间的对象都会被分配到default中。
kube-system Kubernetes系统对象(控制平面和Node组件)所使用的命名空间。.
kube-public自动创建的公共命名空间,所有用户〈包括未经过身份验证的用户)都可以读取它。通常我们约定,将整个集群中公用的可见和可读的资源放在这个空间中。
kube-node-lease租约(Lease)对象使用的命名空间。每个节点都有一个关联的lease对象,lease是一种轻量级资源。lease对象通过发送心跳,检测集群中的每个节点是否发生故障。
使用kubectl get lease -A查看lease对象
# 创建命名空间
kubectl create ns develop
#运行容器的时候制定命名空间
kubectl run nginx --image=nginx:1.22 -n=develop
#不指定查询的都是默认命名空间
kubectl get pod -n=develop
#指定默认命名空间
kubectl config set-context $(kubectl config-context) --namespace=develop
#删除命名空间(状态错误或者资源被占用)
delete ns develop声明式API
命令行指令
例如kubectl命令来创建和管理k8s对象
命令就好比简单传达,简单快速高效
但它功能有限,不适合复杂场景,操作不容易追溯,多用于开发和调试
声明式配
k8s使用yaml文件来描述k8s对象.声明式配置就好比是申请表,学习难度大且配置麻烦
好处是操作留痕,适合操作复杂对象,多用于生产
常用命令缩写
| 名称 | 缩写 | Kind |
|---|---|---|
| namespaces | ns | Namespace |
| nodes | no | Node |
| pods | po | Pod |
| services | svc | Service |
| deployments | deploy | Deployment |
| replicasets | rs | ReplicaSet |
| statefulsets | sts | StatefulSet |
配置对象
在创建的Kubernetes对象所对应的taml中,需要配置的字段如下
- apiVersion-k8s api的版本
- kind 对象类别,例如Pod,Deployment,Service,ReplicaSet
- metadata 用于描述对象的元数据,包括一个name字符串,uid和可选的namespace
- spec 对象的配置
创建一个yml文件
apiVersion: v1
kind: Pod
metadata:
name: my-nginx
spec:
containers:
- name: nginx
image: nginx:1.22
ports:
- containerPort: 80#使用yml创建 不存在才创建
kubectl apply -f my-pod.yaml
# 删除pod
kubectl delte -f my-pod.yaml标签(Label)附加到对象上(比如pod)上的键值对,用于补充对象的描述信息.
标签使用户能够松散的方式管理对象的映射,而无需客户端存储这些映射
由于一个急群众可能管理成千上万个容器,我们可以使用标签进行高效的进行选择和操作容器集合.
容器运行时
CRi镜像导出
容器运行时接口(CRI)容器运行时接口(中国)
Kubelet运行在每个节点(Node)上,用于管理和维护Pod和容器的状态。运行在每个节点(Node)上,用于管理和维护Pod和容器的状态.
容器运行时接口(CR)是kubelet和容器运行时之间通信的主要协议。它将Kubelet与容器运行时解耦,理论上,实现了CRI接口的容器引擎,都可以作为kubernetes的容器运行时。容器运行时接口(CR)是kubelet和容器运行时之间通信的主要协议.它将Kubelet与容器运行时解耦,理论上,实现了cri接口的容器引擎,都可以作为Kubernetes的容器运行时.
Docker没有实现(CRI)接口,Kubernetes使用dockershim来兼容docker。自V1.24版本起,Dockershim已从 Kubernetes码头没有实现(CRI)接口,Kubernetes使用码头来兼容码头。自V1.24版本起,Dockershim已从Kubernetes
项目中移除。项目中移除.
crictl是一个兼容CRI的容器运行时命令,他的用法跟docker 命令一样,可以用来检查和调试底层的运行时容器。蟋蟀是一个兼容的容器运行时命令,他的用法跟命令一样,可以用来检查和调试底层的运行时容器.
在一些局域网环境下,我们没办法通过互联网拉取镜像,可以手动的导出导入镜像
运行有状态应用
- 配置文件-configMap
- 保存密码Secret
- 数据存储--持久卷(PV)和持久卷声明
- 动态创建卷 存储类(StorageClass)6567655
- 部署多个实例statefulSet
- 数据库访问Headless Service
- 主从复制 初始化容器和sidecar
- 数据库调试 port-worward
- 部署mysql集群-helm
创建mysql实例
配置文件
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
ports:
- containerPort: 3306
volumeMounts:
- mountPath: /var/lib/mysql #容器中的目录,因为mysql的数据存在这里了
name: data-volume
volumes: #创建卷
- name: data-volume #卷名
hostPath:
# 映射到的宿主机上目录位置
path: /home/mysql/data
type: DirectoryOrCreate #类型为目录执行
sudo kubectl apply -f mysql.ymlconfigMap
在docker中我们一般可以通过绑定挂载的方式将配置文件挂载到容器里
在k8s集群中,容器可能被调度到任意节点,配置文件需要再集群任意节点上访问分发和更新
configMap用来在键值对数据库(ETCD)中保存非加密数据.一般用来保存配置文件
ConfigMapConfigMap
ConfigMap用来在键值对数据库(etcd)中保存非加密数据。一般用来保存配置文件。ConfigMap 可以用作环境变量、命令行参数或者存储卷。ConfigMap用来在键值对数据库(Etcd)中保存非加密数据一般用来保存配置文件.ConfigMap可以用作环境变量、命令行参数或者存储卷
ConfigMap 将环境配置信息与容器镜像解耦,便于配置的修改。ConfigMap在设计上不是用来保存大量数据的。ConfigMap将环境配置信息与容器镜像解耦,便于配置的修改ConfigMap在设计上不是用来保存大量数据的
在ConfigMap中保存的数据不可超过1MiB。在ConfigMap中保存的数据不可超过1 MiB.
超出此限制,需要考虑挂载存储卷或者访问文件存储服务。超出此限制,需要考虑挂载存储卷或者访问文件存储服务.
创建configMap
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
volumeMounts:
- mountPath: /var/lib/mysql #这里挂载的是数据
name: data-volume
- mountPath: /etc/mysql/conf.d #这里挂载的是配置
name: conf-volume
readOnly: true #配置文件设置为只读
volumes:
- name: conf-volume
configMap:
name: mysql-config #将mysql-config挂载到上面的conf-volume也就是挂载配置文件
- name: data-volume
hostPath:
# directory location on host
path: /home/mysql/data
# this field is optional
type: DirectoryOrCreate
---
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql-config #mysql-config
data:
mysql.cnf: |
[mysqld]
character-set-server=utf8mb4
collation-server=utf8mb4_general_ci
init-connect='SET NAMES utf8mb4'
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4创建
#创建pod
sudo kubectl apply -f mysql.yml
#查看mysql的configmap
sudo kubectl describe cm mysql-config
#进入mysqlpod
exec -it mysql-pod -- bash
#连接数据库
mysql -uroot -p123456
#查看字符集
show variables like '%char%';Secret
Secret用于保存机密数据的对象。一般由于保存密码、令牌或密钥等。data字段用来存储base64编码数据。
stringData存储未编码的字符串。
Secret意味着你不需要在应用程序代码中包含机密数据,减少机密数据(如密码)泄露的风险。
Secret可以用作环境变量、命令行参数或者存储卷文件。
卷Volume
将数据存储在容器中,一但容器被删除,数据也会被删除.
卷是独立容器之外的一块存储区域,挂载Mount的方式供Pod中的容器使用
- 卷可以在多个容器之间共享数据
- 卷可以将容器数据存储在外部存储或云存储上.
- 卷更容易备份迁移.
常见的卷类型
临时卷(Ephemeral Volume):与Pod一起创建和删除,生命周期与Pod 相同
emptyDir -作为缓存或存储日志
configMap . secret、downwardAPI-给Pod注入数据·持久卷(Persistent Volume):删除Pod后,持久卷不会被删除
本地存储- hostPath、local
网络存储–NFS
分布式存储– Ceph(cephfs文件存储、rbd块存储)
投射卷(Projected Volumes): projected卷可以将多个卷映射到同一个目录上
临时卷EV
Ephemeral Volume
- 与pod一起创建删除,生命周期与pod相同
- emptyDir 初始内容为空的本地临时目录(创建一个初始状态为空的目录,存储空间来自本地的kubelet根目录或内存)
- configMap 为Pod注入配置文件
- secret 为pod注入加密数据
configMap卷和Secret卷
这里的configMap和Secret代表的是卷的类型,不是configMap和Secret对象.删除pod不会删除configMap和secret对象
configMap卷和Secret卷是一种特殊类型的卷,kubelet引用configMap和Secret中定义的内容,在pod所在的节点上生成一个临时卷,将数据注入到Pod中.删除Pod,临时卷也会被删除
临时卷位于Pod所在节点的/var/lib/kubelet/pods
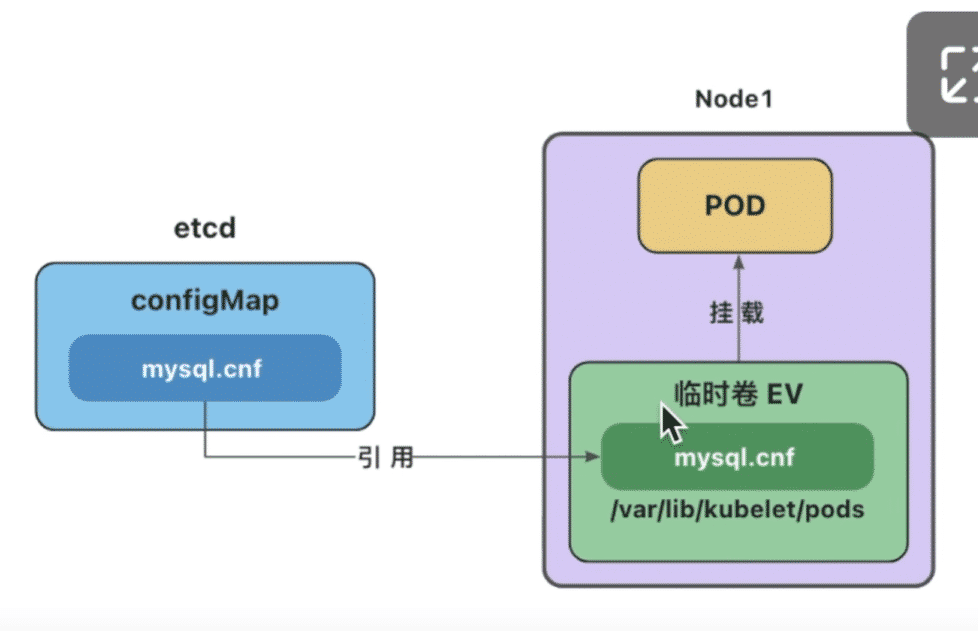
比如刚才的mysql.cnf就会被挂载到pod上
#查看configMap
sudo kubectl get cm持久卷
持久卷(Persistent Volume):删除Pod后,卷不会被删除
本地存储
- hostPath -节点主机上的目录或文件(仅供单节点测试使用;多节点集群请用local卷代替)
- local -节点上挂载的本地存储设备(不支持动态创建卷)
网络存储
- NFS -网络文件系统(NFS)○分布式存储
分布式存储
- Ceph(cephfs文件存储、rbd块存储)
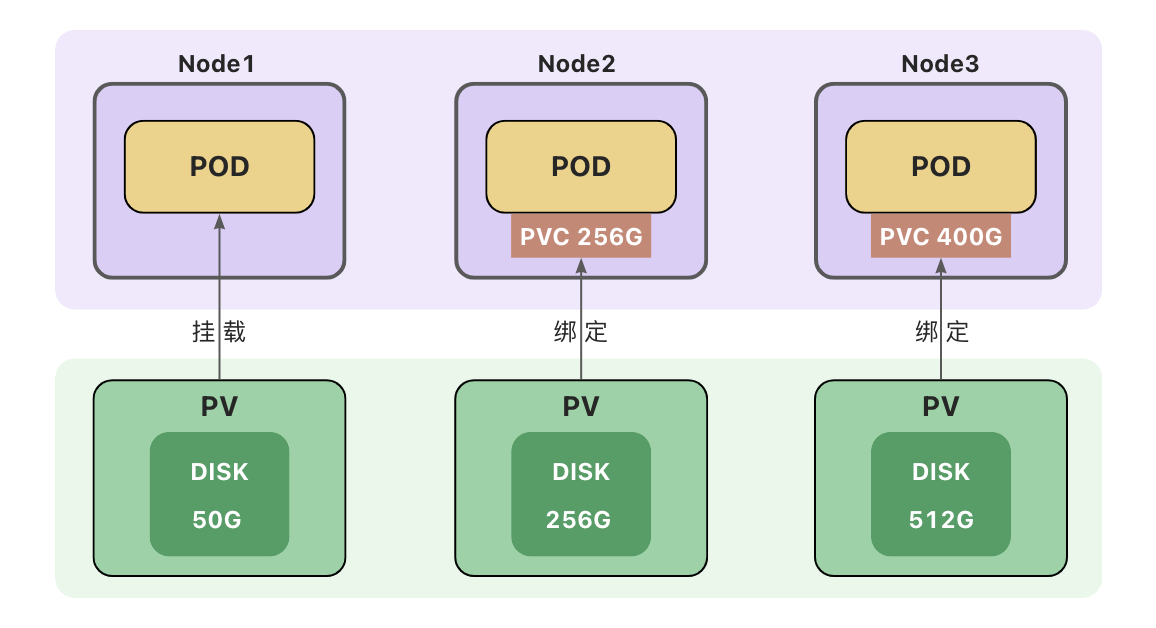
持久卷(PV)和持久卷声明(PVC)
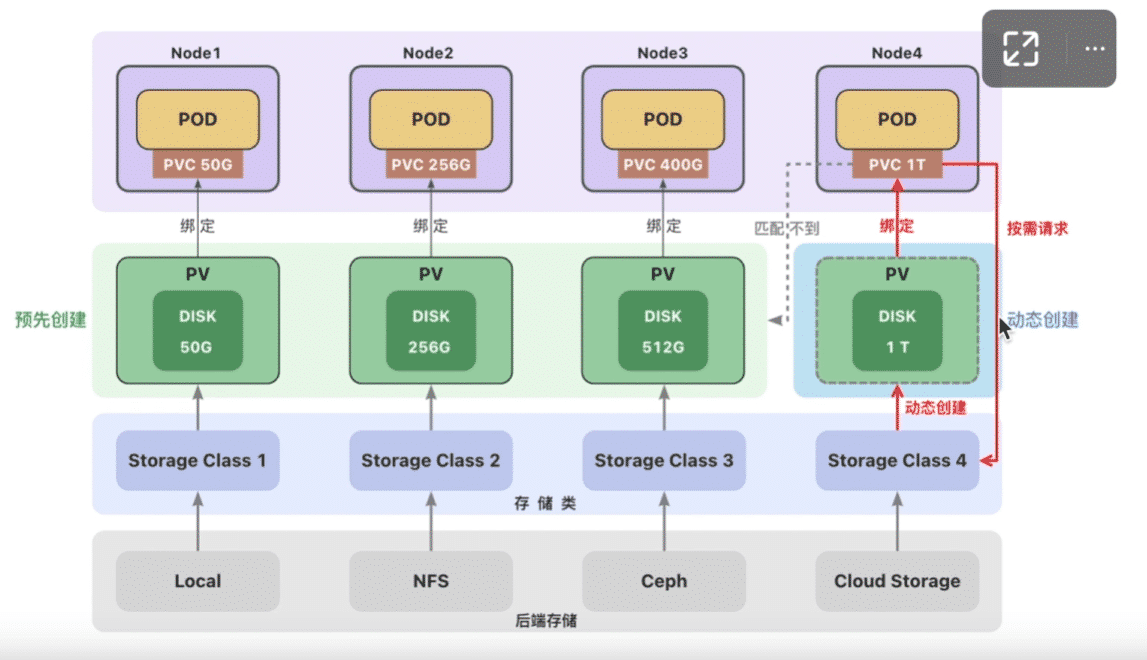
持久卷(PersistentVolume,PV)是集群中的一块存储。可以理解为一块虚拟硬盘。持久卷可以由管理员事先创建,或者使用存储类
(Storage Class)根据用户请求来动态
创建。
持久卷属于集群的公共资源,并不属于某个namespace ;
持久卷声明(PersistentVolumeClaim,PVC)
表达的是用户对存储的请求。
PVC声明好比申请单,它更贴近云服务的使用场景,使用资源先申请,便于统计和计费。Pod 将PVC声明当做存储卷来使用,PVC可以请求指定容量的存储空间和访问模式。PVC对象是带有namespace的。
创建持久卷(PV)是服务端的行为,通常集群管理员会提前创建一些常用规格的持久卷以备使用。
hostPath仅供单节点测试使用,当Pod被重新创建时,可能会被调度到与原先不同的节点上,导致新的Pod没有数据。多节点集群使用本地存储,可以使用local卷
创建local类型的持久卷,需要先创建存储类(StorageClass)。
本地存储类示例
# 创建本地存储类
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: Immediate #绑定模式local卷不支持动态创建,必须手动创建持久卷(PV)
创建local类型的持久卷,必须设置nodeAffinity节点亲和性
调度器使用nodeAffinity信息来使用local卷的pod调度到持久卷所在的节点上,不会出现pod被调度到别的节点的情况.如果节点出现失败,pod会创建失败.
有了存储类后我们就可以创建持久卷了:
# 创建本地存储类
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: Immediate #绑定模式
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: local-pv-1
spec:
capacity:
storage: 4Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage #通过指定存储类来设置卷的类型,和上面的一直
local: #类型为local
path: /mnt/disks/ssd1 #目录
nodeAffinity: #local类型的必须指定节点亲和性
required:
nodeSelectorTerms: #通过节点选择器
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- worker-2 #调度存储到指定的节点上应用
#创建持久节点 返回了俩个成功创建的节点
nsyl@k8s-master:~/Public$ sudo kubectl apply -f local-storage.yaml
storageclass.storage.k8s.io/local-storage created
persistentvolume/local-pv-1
#查看持久卷
kubectl get pv持久卷声明(PVC)
是用户端的行为,用户在创建Pod时,无法知道集群中PV的状态(名称、容量、是否可用等),用户也无需关心这些内容,只需要在声明中提出申请,集群会自动匹配符合需求的持久卷(PV)。
Pod使用持久卷声明(PVC)作为存储卷。
创建pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: local-pv-claim
spec:
storageClassName: local-storage # 与PV中的storageClassName一致
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi#创建
sudo kubectl apply -f pvc.yaml
#这时候再去查看会发现变成了绑定bound的状态 claim变为default/local-pv-claim
sudo kubectl apply -f pvc.yaml
Pod 的配置文件指定了 PersistentVolumeClaim(PVC),但没有指定 PersistentVolume。(PV)
对 Pod 而言,PersistentVolumeClaim 就是一个存储卷。
Pod可以直接使用持久卷也可以使用持久卷声明
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
ports:
- containerPort: 3306
volumeMounts:
- mountPath: /var/lib/mysql #容器中的目录
name: local-mysql-data
volumes:
- name: local-mysql-data
persistentVolumeClaim:
claimName: local-pv-claim绑定
创建持久卷声明(PVC)之后,集群会查找满足要求的持久卷(PV),将 PVC 绑定到该 PV上。
PVC与PV之间的绑定是一对一的映射关系,绑定具有排他性,一旦绑定关系建立,该PV无法被其他PVC使用。
PVC可能会匹配到比声明容量大的持久卷,但是不会匹配比声明容量小的持久卷。
例如,即使集群上存在多个 50 G大小的 PV ,他们加起来的容量大于100G,也无法匹配100 G大小的 PVC。
找不到满足要求的 PV ,PVC会无限期地处于未绑定状态(Pending) , 直到出现了满足要求的 PV时,PVC才会被绑定。
删除pod持久卷和持久卷声明不会被删除
持久卷声明被删除后,不支持自动回收
需要手动删除持久卷
访问模式
- ReadWriteOnce
- 卷可以被一个节点以读写方式挂载,并允许同一节点上的多个 Pod 访问。
- ReadOnlyMany
- 卷可以被多个节点以只读方式挂载。
- ReadWriteMany
- 卷可以被多个节点以读写方式挂载。
- ReadWriteOncePod
- 卷可以被单个 Pod 以读写方式挂载。 集群中只有一个 Pod 可以读取或写入该 PVC。
- 只支持 CSI 卷以及需要 Kubernetes 1.22 以上版本。
卷的状态
- Available(可用)-- 卷是一个空闲资源,尚未绑定到任何;
- Bound(已绑定)-- 该卷已经绑定到某个持久卷声明上;
- Released(已释放)-- 所绑定的声明已被删除,但是资源尚未被集群回收;
- Failed(失败)-- 卷的自动回收操作失败。
卷模式
卷模式(volumeMode)是一个可选参数。
针对 PV 持久卷,Kubernetes 支持两种卷模式(volumeModes):
- Filesystem(文件系统)
默认的卷模式。
- Block(块)
将卷作为原始块设备来使用。
storage会匹配最少差距
存储类
- 静态创建
- 管理员预先手动创建
- 手动创建麻烦、不够灵活(
local卷不支持动态创建,必须手动创建PV) - 资源浪费(例如一个PVC可能匹配到比声明容量大的卷)
- 对自动化工具不够友好
- 动态创建
- 根据用户请求按需创建持久卷,在用户请求时自动创建
- 动态创建需要使用存储类(StorageClass)
- 用户需要在持久卷声明(PVC)中指定存储类来自动创建声明中的卷。
- 如果没有指定存储类,使用集群中默认的存储类
存储类storageClass
一个集群存在多个存储类来创建和管理不同类型的存储.每个storangeClass都有一个制备器(provisioner),用来决定哪个插件制备PV.该字段必须指定
一般使用静态创建和动态创建结合的方式.管理员实现从手动创建一些常规规格的持久卷以备使用,集群也可以根据用户请求动态创建持久卷
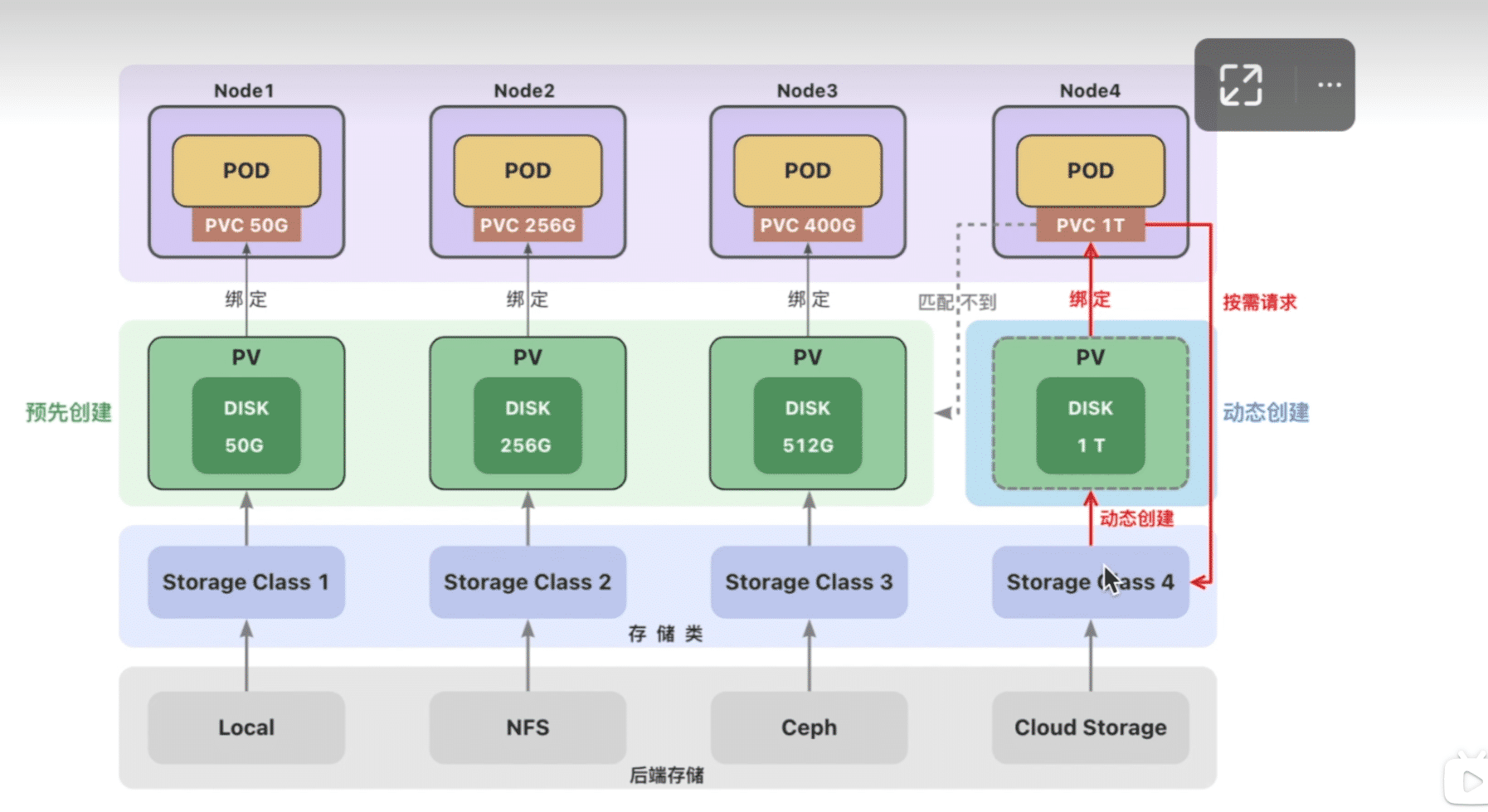
当持久卷匹配不到的时候会动态创建持久卷
#查看存储类
kubectl get sc
kubectl get nodek3s自带了一个名为local-path的存储3类,它支持动态创建基于hostpath或local的持久卷
创建pvc后,会自动创建pv,不需要在手动创建PV
删除pvc,pv也会被删除
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: local-path-pvc
namespace: default
spec:
accessModes:
- ReadWriteOnce
storageClassName: local-path
resources:
requests:
storage: 2Gi
---
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
ports:
- containerPort: 3306
volumeMounts:
- mountPath: /var/lib/mysql #容器中的目录
name: local-mysql-data
volumes:
- name: local-mysql-data
persistentVolumeClaim:
claimName: local-path-pvc卷绑定模式
volumeBindingMode用于控制什么时候动态创建卷和绑定卷。
●Immediate立即创建
创建PVC后,立即创建PV并完成绑定。
●WaitForFirstConsumer 延迟创建
当使用该PVC的 Pod 被创建时,才会自动创建PV并完成绑定。
回收策略(Reclaim Policy)
回收策略告诉集群,当用户删除PVC 对象时, 从PVC中释放出来的PV将被如何处理。
●删除(Delete)
如果没有指定,默认为Delete
当PVC被删除时,关联的PV 对象也会被自动删除。
●保留(Retain)
当 PVC 对象被删除时,PV 卷仍然存在,数据卷状态变为"已释放(Released)"。
此时卷上仍保留有数据,该卷还不能用于其他PVC。需要手动删除PV。
StatefulSet有状态应用集
如果我们需要部署多个MySQL实例,就需要用到有StatefulSet,是用来管理有状态的应用.一般用来管理数据库,缓存等,与deployment类似,StatefulSet用来管理Pod集合的部署和扩展Deployment用来部署无状态应用,StatefulSet用来部署有状态应用.
创建一个StatefulSet
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql # 必须匹配 .spec.template.metadata.labels
serviceName: db
replicas: 3 # 默认值是 1 这里设置3个mysql
minReadySeconds: 10 # 默认值是 0
template:
metadata:
labels:
app: mysql # 必须匹配 .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
ports:
- containerPort: 3306
volumeMounts:
- mountPath: /var/lib/mysql #容器中的目录
name: mysql-data
volumeClaimTemplates:
- metadata:
name: mysql-data
spec:
accessModes:
- ReadWriteOnce
storageClassName: local-path
resources:
requests:
storage: 2Gi执行
#创建 创建是依次创建的
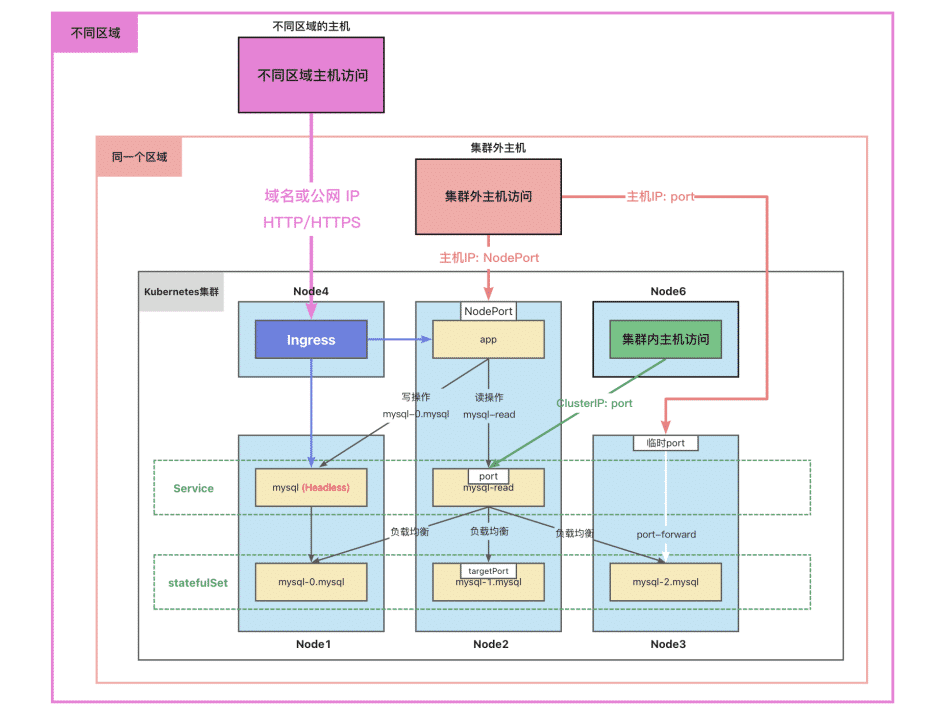
sudo kubectl apply -f statefulSet.yml无头服务
我们刚才创建了三个各自独立的数据库实例,要想让别的容器访问数据库,我们需要将它发布为service,但是service带负载均衡功能.每次请求都会转发给不同的数据库,这样子使用过程中会产生很大的问题
无头服务(HeadLess Service)可以为StatefulSet成员提供稳定的DNS地址.
在不需要负载均衡的情况下,可以通过制定ClusterIp的值来为None来创建无头服务.
注意:statefulSet中的ServiceName必须要根Service中的metadata.name一致
# 为 StatefulSet 成员提供稳定的 DNS 表项的无头服务(Headless Service)
apiVersion: v1
kind: Service
metadata:
#重要!这里的名字要跟后面StatefulSet里ServiceName一致
name: db
labels:
app: database
spec:
ports:
- name: mysql
port: 3306
# 设置Headless Service
clusterIP: None
selector:
app: mysql
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql # 必须匹配 .spec.template.metadata.labels
serviceName: db #重要!这里的名字要跟Service中metadata.name匹配
replicas: 3 # 默认值是 1
minReadySeconds: 10 # 默认值是 0
template:
metadata:
labels:
app: mysql # 必须匹配 .spec.selector.matchLabels
spec:
terminationGracePeriodSeconds: 10
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
ports:
- containerPort: 3306
volumeMounts:
- mountPath: /var/lib/mysql
name: mysql-data
volumeClaimTemplates:
- metadata:
name: mysql-data
spec:
accessModes:
- ReadWriteOnce
storageClassName: local-path
resources:
requests:
storage: 2Gi稳定的网络ID
StatefulSet 中的每个 Pod 都会被分配一个StatefulSet名称-序号格式的主机名。
集群内置的DNS会为Service分配一个内部域名db.default.svc.cluster.local,它的格式为 服务名称.命名空间.svc.cluster.local。
Service下的每个Pod会被分配一个子域名,格式为pod名称.所属服务的域名,例如mysql-0的域名为mysql-0.db.default.svc.cluster.local。
创建Pod时,DNS域名生效可能会有一些延迟(几秒或几十秒)。
Pod之间可以通过DNS域名访问,同一个命名空间下可以省略命名空间及其之后的内容。
kubectl run dns-test -it --image=busybox:1.28 --rm
# 访问mysql-0数据库
nslookup mysql-0.db初始化容器
初始化容器(Init Containers)
初始化容器(Init Containers)是一种特殊容器,它在Pod内的应用容器启动之前运行。初始化容器未执行完毕或以错误状态退出,Pod内的应用容器不会启动。
初始化容器需要在initContainers中定义,与containers同级。基于上面的特性,初始化容器通常用于
- 生成配置文件
- 执行初始化命令或脚本
- 执行健康检查(检查依赖的服务是否处于Ready或健康Health的状态)
边车Sidecar
Pod中运行了2个容器,MySQL容器和一个充当辅助工具的xtrabackup容器,我们称
之
为边车(sidecar)。
Xtrabackup是一个开源的MySQL备份工具,支持在线热备份(备份时不影响数据读写),是目前各个云厂商普遍使用的MySQL备份工具。
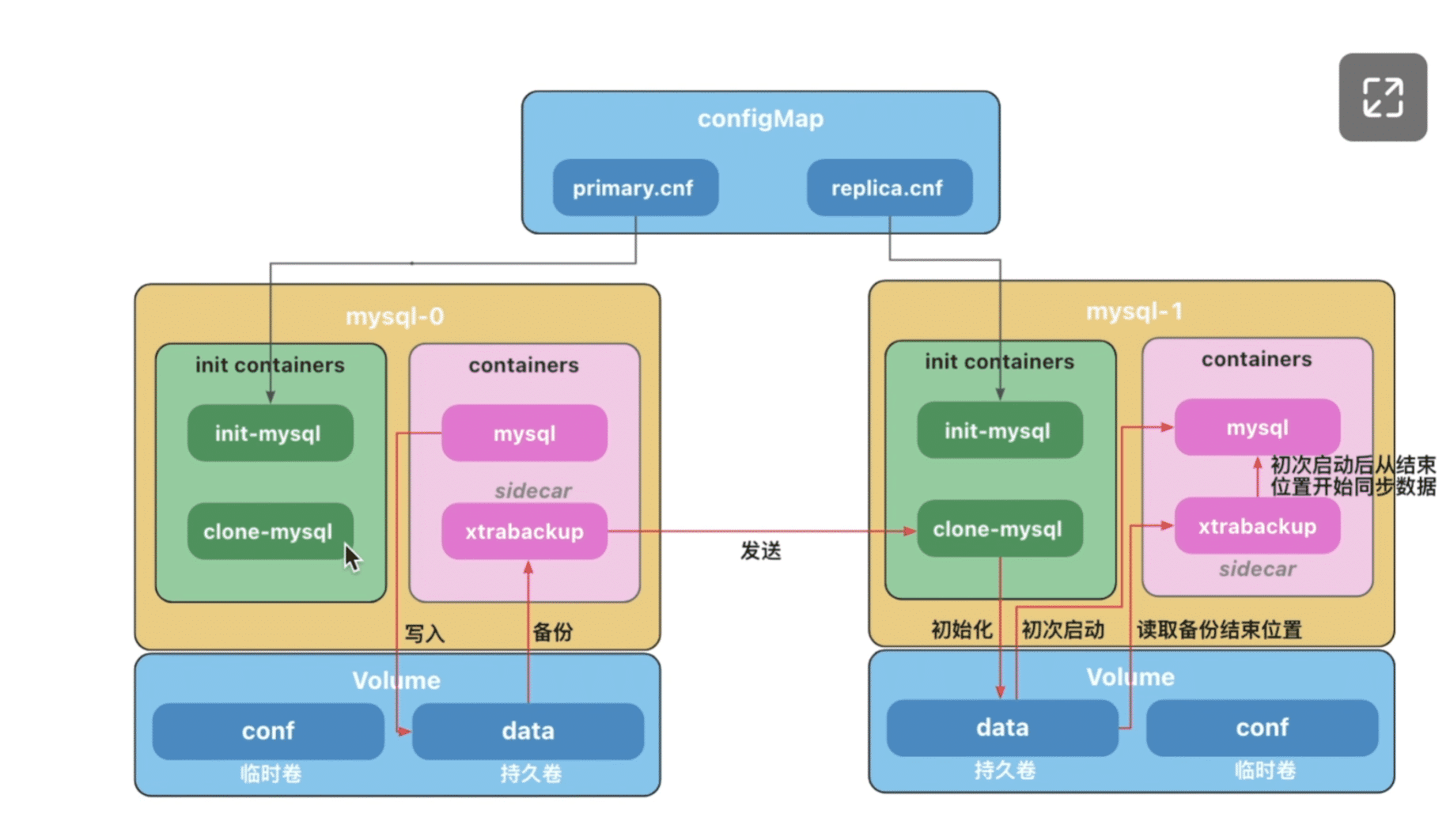
sidecar容器负责将备份的数据文件发送给下一个Pod ,并在副本服务器初次启动时,使用数据文件完成数据的导入。
MySQL使用bin-log同步数据,但是,当数据库运行一段时间后,产生了一些数据,这时候如果我们进行扩容,创建了一个新的副本,有可能追溯不到bin-log的源头(可能被手动清理或者过期自动删除),因此需要将现有的数据导入到副本之后,再开启数据同步, sidecar 只负责数据库初次启动时完成历史数据导入,后续的数据MySQL会自动同步。
端口转发
通常,集群中的数据库不直接对外访问。
但是,有时候我们需要图形化工具连接到数据库进行操作或者调试。
我们可以使用端口转发来访问集群中的应用。
kubectl port-forward可以将本地端口的连接转发给容器。
此命令在前台运行,命令终止后,转发会话将结束。
这种类型的连接对数据库调试很有用。
#主机端口在前,容器端口在后
#如果主机有多个IP,需要指定IP,如不指定IP,默认为127.0.0.1
kubectl port-forward pods/mysql-0 --address=192.168.56.109 33060:3306网络访问
- 容器中应用访问数据库:
- 读操作:mysql-read:3306
- 写操作:mysql-0.mysql:3306
- 集群中的Node访问:
- ClusterIP:port
- 集群外的主机访问:
- 主机IP:nodePort
helm
Helm 是一个 Kubernetes 应用的包管理工具,类似于 Ubuntu 的 APT 和 CentOS 中的 YUM。
Helm使用chart 来封装kubernetes应用的 YAML 文件,我们只需要设置自己的参数,就可以实现自动化的快速部署应用。
安装Helm
下载安装包:
https://github.com/helm/helm/releases
https://get.helm.sh/helm-v3.10.0-linux-amd64.tar.gz
mv linux-amd64/helm /usr/local/bin/helm
在K3s中使用,需要配置环境变量
export KUBECONFIG=/etc/rancher/k3s/k3s.yaml
三大概念
- Chart 代表着 Helm 包。
- 它包含运行应用程序需要的所有资源定义和依赖,相当于模版。
- 类似于maven中的
pom.xml、Apt中的dpkb或 Yum中的RPM。 - Repository(仓库) 用来存放和共享 charts。
- 不用的应用放在不同的仓库中。
- Release 是运行 chart 的实例。
一个 chart 通常可以在同一个集群中安装多次。
每一次安装都会创建一个新的 release,**release name**不能重复。
Helm仓库
Helm有一个跟docker Hub类似的应用中心(https://artifacthub.io/),我们可以在里面找到我们需要部署的应用。
安装单节点Mysql
#添加仓库
helm repo add bitnami https://charts.bitnami.com/bitnami
#查看chart
helm show chart bitnami/mysql
#查看默认值
helm show values bitnami/mysql
#安装mysql
helm install my-mysql \
--set-string auth.rootPassword="123456" \
--set primary.persistence.size=2Gi \
bitnami/mysql
#查看设置
helm get values my-mysql
#删除mysql
helm delete my-releaseHelm部署MySQL集群
安装过程中有两种方式传递配置数据:
●-f (或--values):使用 YAML 文件覆盖默认配置。可以指定多次,优先使用最右边的文件。
●--set:通过命令行的方式对指定项进行覆盖。
如果同时使用两种方式,则 --set中的值会被合并到 -f中,但是 --set中的值优先级更高。
使用配置文件设置MySQL的参数。
auth:
rootPassword: "123456"
primary:
persistence:
size: 2Gi
enabled: true
secondary:
replicaCount: 2
persistence:
size: 2Gi
enabled: true
architecture: replicationhelm install my-db -f values.yaml bitnami/mysql