AST abstract syntax Tree
简介
抽象语法树是一种用编程语言编写的源代码的抽象语法结构的树表示。树的每个节点表示源代码中出现的一个构造。
AST全称为Abstract Syntax Tree,抽象语法树。
AST在编译器的应用非常重要,因为抽象语法树是编译器中广泛用于表示程序代码结构的数据结构。AST通常是编译器语法分析阶段的结果。它通常过编译器所需的几个阶段作为程序的中间表示,并且对编译器的最终输出有很大影响。
在进一步讨论实现部分之前,让我们先讨论一下AST的使用。AST主要用于编译器一检查代码的准确性。如果生成的语法树有错误,编译器会打印一条错误信息。使用抽象语法树(AST)是因为某些构造无法用上下文无关语法表示,列如隐式类型。它们高度特定于编程语言,但对通用语法树的研究正在进行中。
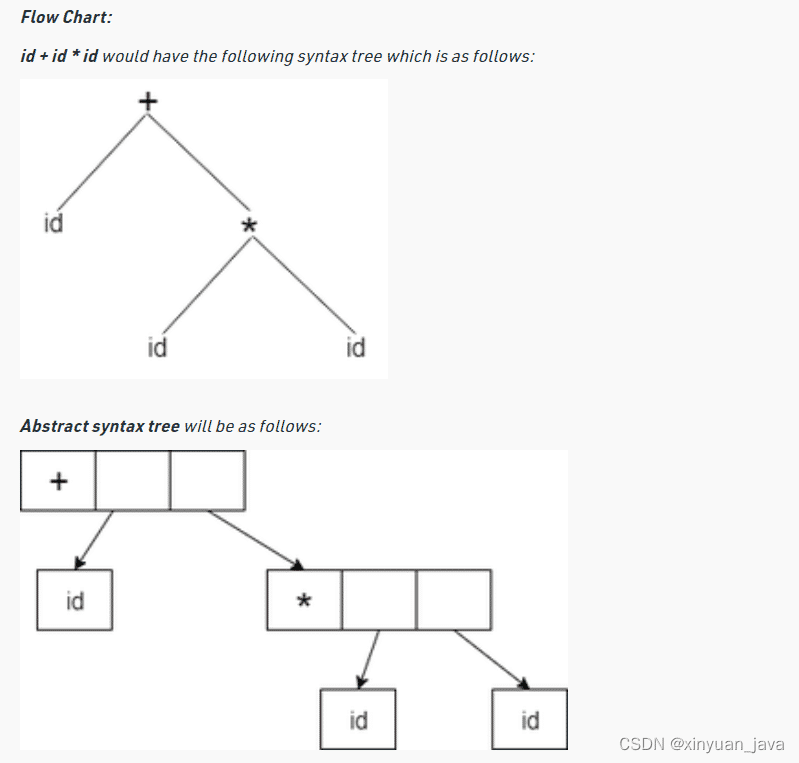
在java中AST通常由一个解析器创建,该解析器读取原地阿妈并创建一个树形结构,代表代码的语法和结构。树中的每个节点都代表一个不同的语法结构,如类、方法或语句。
一般来说,AST是编译器和其他需要分析和处理编程语言语法的工具的重要工具。
作用AST有什么作用了?用过lombok的人一定能感觉到那种简洁舒服的代码风格,lombok的原理也就是在代码编译的时候根据相应的注解动态的去修改AST这个树,为它增加新的节点(也就是对于的代码比如get、set)。所以如果想动态的修改代码,或者直接生成java代码的话,AST是一个不错的选择。
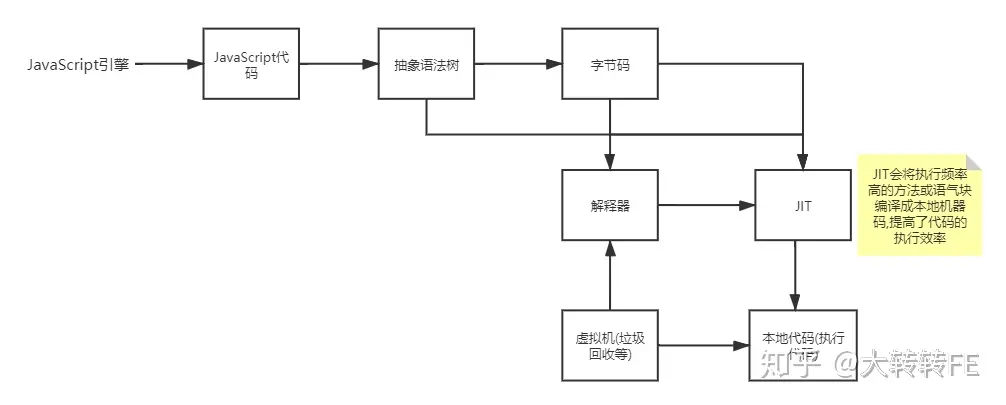
什么是AST抽象语法树
我们都知道,在传统的编译语言的流程中,程序的一段源代码在执行之前会经历三个步骤,统称为"编译":
- 分词/词法分析
这个过程会将由字符组成的字符串分解成有意义的代码块,这些代码块统称为词法单元(token).
举个例子: let a = 1, 这段程序通常会被分解成为下面这些词法单元: let 、a、=、1、 ;空格是否被当成此法单元,取决于空格在这门语言中的意义。
- 解析/语法分析
这个过程是将词法单元流转换成一个由元素嵌套所组成的代表了程序语法结构的树,这个树被称为"抽象语法树"(abstract syntax code,AST) - 代码生成
将AST转换成可执行代码的过程被称为代码生成.
抽象语法树(abstract syntax code ,AST)是源代码的抽象语法结构的树状表示,树上的每个节点都表示源代码中的一种结构,之所以说是抽象的,抽象表示把js代码进行了结构化的转化,转化为一种数据结构。这种数据结构其实就是一个大的json对象,json我们都熟悉,他就像一颗枝繁叶茂的树。有树根,有树干,有树枝,有树叶,无论多小多大,都是一棵完整的树。
简单理解,就是把我们写的代码按照一定的规则转换成一种树形结构。
用途
AST不仅仅是用来Js引擎的编译上,我们实际开发过程中也是经常使用的,比如我们常用的babel插件自动将ES6的语法转换成ES5、使用 UglifyJS来压缩代码 、css预处理器、开发WebPack插件、Vue-cli前端自动化工具等等,这些底层原理都是基于AST来实现的,AST能力十分强大, 能够帮助开发者理解JavaScript这门语言的精髓。
结构
我们先来简单看一组AST树状结构
const team = '大转转FE'经过转换,输出如下AST树桩结构
{
"type": "Program",
"start": 0,
"end": 18,
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 18,
"declarations": [
{
"type": "VariableDeclarator",
"start": 6,
"end": 18,
"id": {
"type": "Identifier",
"start": 6,
"end": 8,
"name": "team"
},
"init": {
"type": "Literal",
"start": 11,
"end": 18,
"value": "大转转FE",
"raw": "'大转转FE'"
}
}
],
"kind": "const"
}
],
"sourceType": "module"
}我们可以看到,一个标准的AST结构可以理解为一个json对象,那我们就可以通过一些方法去解析和操作它
Esprima: Parser测试网址
AST编译过程

词法分析
var company = 'zhuanzhuan'假如有以上代码,在词法分析阶段,回显对整个代码进行扫描,生成tokens流,扫描过程如下
- 我们会通过条件判断这个字符是字母, "/" , "数字" , 空格 , "(" , ")" , ";" 等等。
- 如果是字母会继续往下看如果还是字母或者数字,会继续这一过程直到不是为止,这个时候发现找到的这个字符串是一个var,是一个关键字,并且下一个字符是一个空格,就会生成{ "type" : "Keyword" , "value" : "var" }放入数组中
- 它继续向下找发现了一个字母company(因为找到的上一个值是var这个时候如果它发现下一个字符不是字母就可能直接会报错并返回)并且后面是空格生成{ "type" : "Identifier" , "value" : "company" }放到数组中
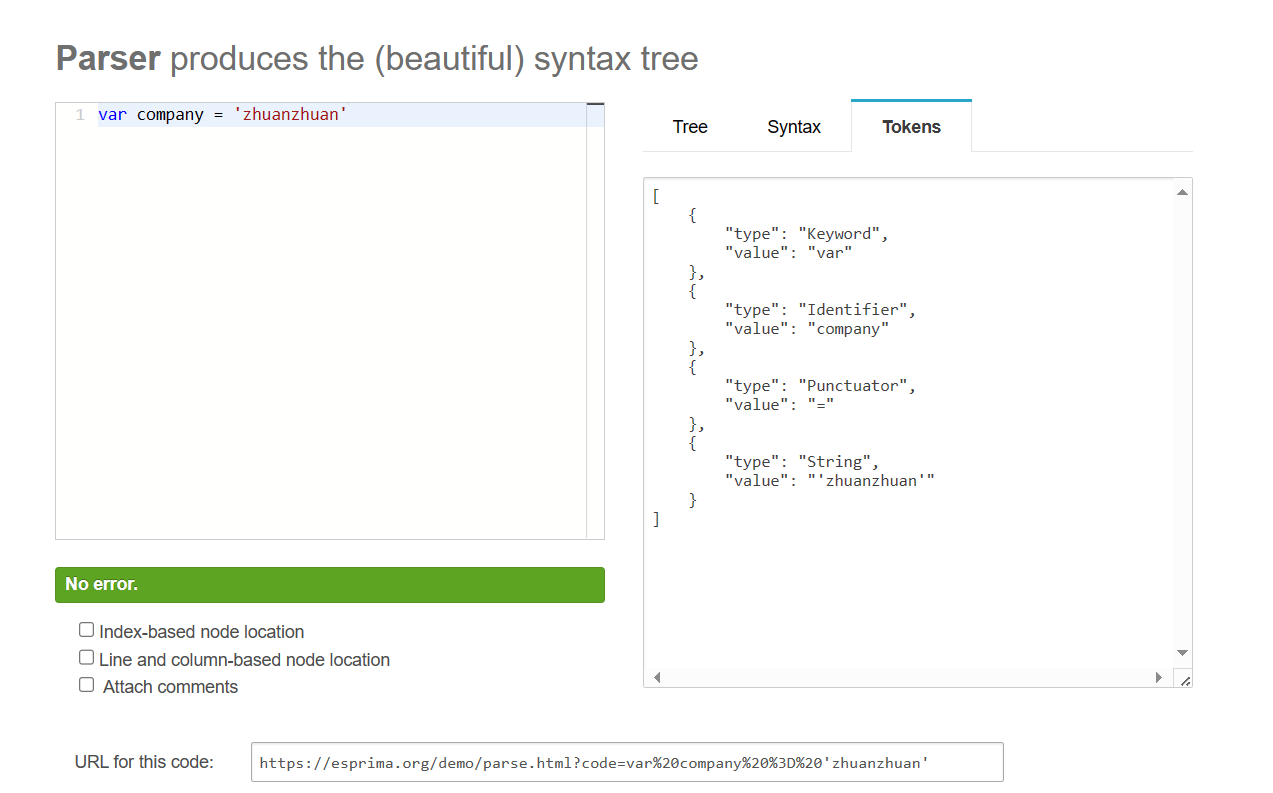
syntax
{
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "company"
},
"init": {
"type": "Literal",
"value": "zhuanzhuan",
"raw": "'zhuanzhuan'"
}
}
],
"kind": "var"
}
],
"sourceType": "script"
}parser生成AST树
这里我们使用esprima去生成, 安装相关依赖 npm i esprima --save
以如下代码为例:
const company = 'zhuanzhuan'要得到其对应的AST,我们对其进行如下操作:
const esprima = require('esprima');
let code = 'const company = "zhuanzhuan" ';
const ast = esprima.parseScript(code);
console.log(ast);运行结果如下:
$ node test.js
Script {
type: 'Program',
body: [
VariableDeclaration {
type: 'VariableDeclaration',
declarations: [Array],
kind: 'const'
}
],
sourceType: 'script'
}这样我们就得到了一棵AST树
traverse对AST树遍历,进行增删改查
这里我们使用estraverse去完成, 安装相关依赖 npm i estraverse --save
还是上面的代码, 我们更改为 const team = '大转转FE'
const esprima = require('esprima');
const estraverse = require('estraverse');
let code = 'const company = "zhuanzhuan" ';
const ast = esprima.parseScript(code);
estraverse.traverse(ast, {
enter: function (node) {
node.name = 'team';
node.value = "大转转FE";
}
});
console.log(ast);运行结果如下:
$ node test.js
Script {
type: 'Program',
body: [
VariableDeclaration {
type: 'VariableDeclaration',
declarations: [Array],
kind: 'const',
name: 'team',
value: '大转转FE'
}
],
sourceType: 'script',
name: 'team',
value: '大转转FE'
}这样一来,我们就完成了对AST的遍历更新。
generator将更新后的AST转化成代码
这里我们使用escodegen去生成, 安装相关依赖 npm i escodegen --save
整体代码结构如下:
const esprima = require('esprima');
const estraverse = require('estraverse');
const escodegen = require('escodegen');
let code = 'const company = "zhuanzhuan" ';
const ast = esprima.parseScript(code);
estraverse.traverse(ast, {
enter: function (node) {
node.name = 'team';
node.value = "大转转FE";
}
});
const transformCode = escodegen.generate(ast);
console.log(transformCode);会得到如下结果:
$ node test.js
const team = '大转转FE';这样一来,我们就完成了对一段简单代码的AST编译过程。
babel原理浅析
babel的三个主要处理步骤分别是解析(parse)转换(transform),生成(generate)
- 解析
将代码解析成抽象语法树(AST),每个js引擎(比如Chrome浏览器中的V8引擎)都有自己的AST解析器,而Babel是通过Babylon(https://github.com/babel/babylon)实现的。解析过程有两个阶段:词法分析和语法分析,词法分析阶段把字符串形式的代码转换为词元(tokens)流,令牌词元类似于AST中节点;而语法分析阶段则会把一个词元流转换成 AST的形式,同时这个阶段会把词元中的信息转换成AST的表述结构。 - 转换
转换步骤接收 AST 并对其进行遍历,在此过程中对节点进行添加、更新及移除等操作。 Babel通过babel-traverse对其进行深度优先遍历,维护AST树的整体状态,并且可完成对其的替换,删除或者增加节点,这个方法的参数为原始AST和自定义的转换规则,返回结果为转换后的AST。 - 生成
代码生成)步骤把最终(经过一系列转换之后)的 AST 转换成字符串形式的代码,同时还会创建源码映射(source maps)(http://www.html5rocks.com/en/tutorials/developertools/sourcemaps/)。.
代码生成其实很简单:深度优先遍历整个 AST,然后构建可以表示转换后代码的字符串。
Babel通过babel-generator再转换成js代码,过程就是深度优先遍历整个AST,然后构建可以表示转换后代码的字符串。
Vue中AST抽象语法树的运用
Vue中AST主要用在模板编译过程
我们先来看看vue模板编译的整体流程图:
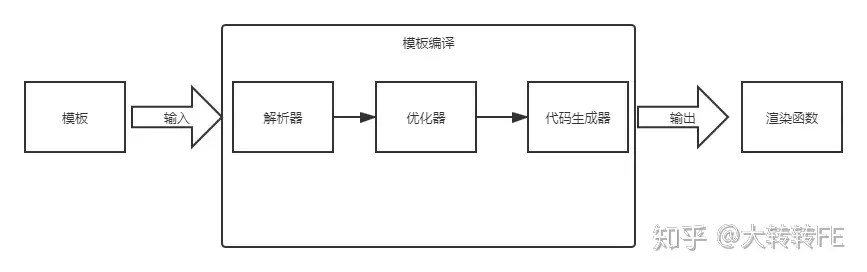
vue的模板编译主要分为三个步骤
- 解析器阶段:将template里面的代码解析成AST抽象语法树
- 优化器阶段:将AST抽象语法树静态表情打上tag,防止重复渲染(优化了diff算法)
- 代码生成阶段:优化后的AST抽象语法树通过generate函数生成rander函数字符串
我们来看看vue源代码整体实现过程
export const createCompiler = createCompilerCreator(function baseCompile (
template: string,
options: CompilerOptions
): CompiledResult {
//生成ast的过程
const ast = parse(template.trim(), options)
//优化ast的过程,给ast抽象语法树静态标签打上tag,防止重复渲染
if (options.optimize !== false) {
optimize(ast, options)
}
//通过generate函数生成render函数字符串
const code = generate(ast, options)
return {
ast,
render: code.render,
staticRenderFns: code.staticRenderFns
}
})解析器要实现的功能就是将模板解析成AST,我们这里主要来分析一下代码解析阶段,这里主要运用的是parse()这个函数,事实上,函数内部也分为好几个解析器,文本解析器以及过滤解析器,其中最主要的就是HTML解析器。HTML解析器的作用是解析HTML,它在解析HTML的过程中会触发各种钩子函数,来看看代码实现
parseHTML(template, {
//解析开始标签
start (tag, attrs, unary, start, end) {
},
//解析结束标签
end (tag, start, end) {
},
//解析文本
chars (text: string, start: number, end: number) {
},
//解析注释
comment (text: string, start, end){
}
})举个例子:
<div>我们是大转转FE</div>当上面这个模板被HTML解析器解析时,所触发的钩子函数依次是: start、chars、end。
所以HTML解析器在实现上是一个函数,它有两个参数----模板和选项,我们的模板是一小段一小段去截取与解析的,所以需要不断循环截取,我们来看看vue内部实现原理:
function parseHTML (html, options) {
while (html) {
//判断父元素为正常标签的元素的逻辑
if (!lastTag || !isPlainTextElement(lastTag)) {
//vue中要判断是 文本、注释、条件注释、DOCTYPE、结束、开始标签
//除了文本标签, 其他的都是以 < 开头, 所以区分处理
var textEnd = html.indexOf('<');
if (textEnd === 0) {
//注释的处理逻辑
if (comment.test(html)) {}
//条件注释的处理逻辑
if (conditionalComment.test(html)) {}
//doctype的处理逻辑
var doctypeMatch = html.match(doctype);
if (doctypeMatch) {}
//结束标签的处理逻辑
var endTagMatch = html.match(endTag);
if (endTagMatch) {}
//开始标签的处理逻辑
var startTagMatch = parseStartTag();
if (startTagMatch) {}
}
var text = (void 0), rest = (void 0), next = (void 0);
//解析文本
if (textEnd >= 0) {}
// "<" 字符在当前 html 字符串中不存在
if (textEnd < 0) {
text = html
html = ''
}
// 如果存在 text 文本
// 调用 options.chars 回调,传入 text 文本
if (options.chars && text) {
// 字符相关回调
options.chars(text)
}
}else{
// 父元素为script、style、textarea的处理逻辑
}
}
}以上就是vue解析器生成AST语法树的主流程了,代码细节的地方还需要自己去解读源码,源码位置:vuepackagesweex-template-compilerbuild.js
AST抽象语法树的知识点作为JavaScript中(任何编程语言中都有ast这个概念,这里就不过多赘述)相对基础的,也是最不可忽略的知识,带给我们的启发是无限可能的,它就像一把螺丝刀,能够拆解javascript这台庞大的机器,让我们能够看到一些本质的东西,同时也能通过它批量构建任何javascript代码。
ShadingSphere的SQL解析引擎
Shadingsphere作为一款分库分表的中间件,分片是其核心功能。分片流程包括SQL解析、SQL路由、SQL改写、SQL执行,结果归并。分片流程的这些流程都对应响应的引擎
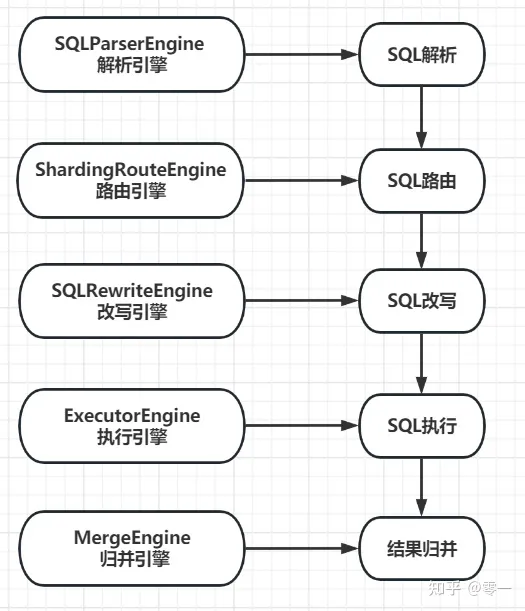
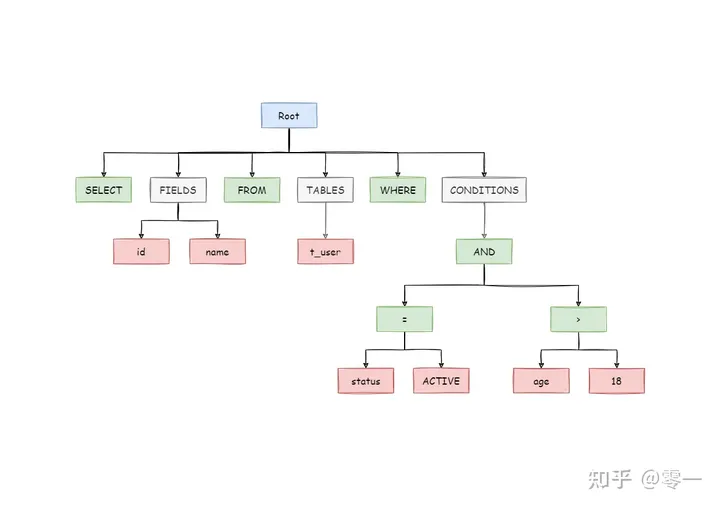
这篇文章只分析SQL解析流程。SQL解析是分片流程中的第一步,是由SQL解析引擎完成SQL解析的。SQL解析分为词法分析和语法解析,首先通过词法解析将SQL语句作为一个不可再分的单词,然后再使用语法解析对SQL进行理解,提炼出解析上下文。解析上下文包括表,选择项,排序项,分组项,聚合函数,分页信息,查询条件以及可能需要修改的占位符的标记
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18抽象语法树如图
shadingsphere中SQL解析流程最终会将SQL语句解析为SQLStatement对象,SQLStatement包括SQL片段对象SQLSegment,SQLStatement对象是解析好的SQL对象。如InsertStatement表示SQL插入语句被shardingsphereSQL解析后的对象,该类如下:
public final class InsertStatement extends DMLStatement {
//表片段
private SimpleTableSegment table;
//插入的字段片段
private InsertColumnsSegment insertColumns;
//set 片段
private SetAssignmentSegment setAssignment;
//On Duplicate Key片段
private OnDuplicateKeyColumnsSegment onDuplicateKeyColumns;
//插入的值片段
private final Collection<InsertValuesSegment> values = new LinkedList<>();
//省略代码
}SQLSegment 对象包含了位置信息,如InsertColumnsSegment包含了插入字段在sql语句中开始位置和结束位置。如:
public final class InsertColumnsSegment implements SQLSegment {
private final int startIndex;
private final int stopIndex;
private final Collection<ColumnSegment> columns;
}有了上述的了解,那么来看看SQL解析引擎SQLParserEngine的入口。在分析《shardingsphere源码阅读-ShardingRuntimeContext分析》中,分析了AbstractRuntimeContext,在该类的构造方法中,会初始化SQLParserEngine,如下:
protected AbstractRuntimeContext(final T rule, final Properties props, final DatabaseType databaseType) {
//省略代码
sqlParserEngine = SQLParserEngineFactory.getSQLParserEngine(DatabaseTypes.getTrunkDatabaseTypeName(databaseType));
//省略代码
}使用SQL引擎工程SQLParserEngineFactory创建了SQLParserEngine,SQLParserEngineFactory类如下:
public final class SQLParserEngineFactory {
//缓存SQLParserEngine
private static final Map<String, SQLParserEngine> ENGINES = new ConcurrentHashMap<>();
public static SQLParserEngine getSQLParserEngine(final String databaseTypeName) {
//根据数据库类型从缓存中获取SQL解析引擎
if (ENGINES.containsKey(databaseTypeName)) {
return ENGINES.get(databaseTypeName);
}
//加锁,再次从缓存中获取,如果没有获取到,直接new一个SQLParserEngine
synchronized (ENGINES) {
if (ENGINES.containsKey(databaseTypeName)) {
return ENGINES.get(databaseTypeName);
}
SQLParserEngine result = new SQLParserEngine(databaseTypeName);
ENGINES.put(databaseTypeName, result);
return result;
}
}
}SQLParserEngineFactory类有一个ENGINES属性,保存着不同数据库类型的SQL解析引擎。getSQLParserEngine方法获取SQL解析引擎。首先根据数据库类型从缓存中获取SQL解析引擎,获取不到,则加锁再次从缓存中获取,如果还获取不到,则直接创建SQLParserEngine并添加到缓存中。获取到SQLParserEngine,就可以进行解析SQL了,SQLParserEngine类如下:
public final class SQLParserEngine {
//数据库类型
private final String databaseTypeName;
//SQL解析结果缓存
private final SQLParseResultCache cache = new SQLParseResultCache();
public SQLStatement parse(final String sql, final boolean useCache) {
//SPI解析钩子
ParsingHook parsingHook = new SPIParsingHook();
//解析钩子启动,将解析前sql作为参数传入
parsingHook.start(sql);
try {
//解析SQL
SQLStatement result = parse0(sql, useCache);
//解析SQL成功后,调用解析钩子的成功方法,将解析结果传入
parsingHook.finishSuccess(result);
return result;
// CHECKSTYLE:OFF
} catch (final Exception ex) {
// CHECKSTYLE:ON
//如果解析失败,将异常作为参数传递给钩子的finishFailure方法
parsingHook.finishFailure(ex);
throw ex;
}
}
private SQLStatement parse0(final String sql, final boolean useCache) {
//如果使用缓存,则从缓存中直接获取SQL解析的结果
if (useCache) {
Optional<SQLStatement> cachedSQLStatement = cache.getSQLStatement(sql);
if (cachedSQLStatement.isPresent()) {
return cachedSQLStatement.get();
}
}
//使用SQL解析执行器,获取解析后的解析树ParseTree
ParseTree parseTree = new SQLParserExecutor(databaseTypeName, sql).execute().getRootNode();
//委托ParseTreeVisitor创建SQLStatement
SQLStatement result = (SQLStatement) ParseTreeVisitorFactory.newInstance(databaseTypeName, VisitorRule.valueOf(parseTree.getClass())).visit(parseTree);
//如果使用缓存,则将解析的SQLStatement加入缓存中
if (useCache) {
cache.put(sql, result);
}
return result;
}
}SQLParserEngine的parse方法,首先创建ParsingHook,用于在SQL解析的跟踪和监控。在SQL解析前,调用parsingHook的start方法,将解析前的SQL作为参数传入。然后调用parse0方法进行解析,解析SQL成功后,调用解析钩子的finishSuccess方法,将解析结果作为参数传入。如果解析过程中发生异常,则调用parsingHook的finishFailure方法,将异常作为参数传入。ParsingHook是一个接口,使用者可以实现ParsingHook的三个方法,可以监控和跟踪解析的前后过程。
parse0方法是真正解析SQL的方法,如果使用缓存,则从缓存中直接获取SQL解析的结果,如果缓存中不存在,则使用SQL解析执行器,获取解析后的解析树ParseTree,然后在委托ParseTreeVisitor创建SQLStatement。ShardingSphere使用ANTLR作为SQL解析的引擎。SQLParserExecutor类将SQL解析为抽象语法树,代码如下:
public final class SQLParserExecutor {
//数据库类型名称
private final String databaseTypeName;
//SQL语句
private final String sql;
public ParseASTNode execute() {
ParseASTNode result = towPhaseParse();
if (result.getRootNode() instanceof ErrorNode) {
throw new SQLParsingException(String.format("Unsupported SQL of `%s`", sql));
}
return result;
}
private ParseASTNode towPhaseParse() {
//根据数据库类型和sql加载SQL解析器
SQLParser sqlParser = SQLParserFactory.newInstance(databaseTypeName, sql);
try {
((Parser) sqlParser).setErrorHandler(new BailErrorStrategy());
((Parser) sqlParser).getInterpreter().setPredictionMode(PredictionMode.SLL);
//解析
return (ParseASTNode) sqlParser.parse();
} catch (final ParseCancellationException ex) {
((Parser) sqlParser).reset();
((Parser) sqlParser).setErrorHandler(new DefaultErrorStrategy());
((Parser) sqlParser).getInterpreter().setPredictionMode(PredictionMode.LL);
return (ParseASTNode) sqlParser.parse();
}
}
}SQLParserExecutor类采用工厂模式很快数据库类型和sql得到不同数据库的SQL解析器。SQLParserFactory类负责获取SQL解析器:
public final class SQLParserFactory {
static {
//注册SQL解析器的配置
NewInstanceServiceLoader.register(SQLParserConfiguration.class);
}
//根据SQL解析器配置获取SQL解析器
public static SQLParser newInstance(final String databaseTypeName, final String sql) {
for (SQLParserConfiguration each : NewInstanceServiceLoader.newServiceInstances(SQLParserConfiguration.class)) {
if (each.getDatabaseTypeName().equals(databaseTypeName)) {
return createSQLParser(sql, each);
}
}
throw new UnsupportedOperationException(String.format("Cannot support database type '%s'", databaseTypeName));
}
@SneakyThrows
//根据SQL解析器获取解析器
private static SQLParser createSQLParser(final String sql, final SQLParserConfiguration configuration) {
Lexer lexer = (Lexer) configuration.getLexerClass().getConstructor(CharStream.class).newInstance(CharStreams.fromString(sql));
return configuration.getParserClass().getConstructor(TokenStream.class).newInstance(new CommonTokenStream(lexer));
}
}SQLParserFactory类根据不同的SQL解析器配置获取不同数据库的SQL解析器,最终获取到ANTLR的SQL解析器Lexer。通过SQLParserExecutor获取到ParseTree,就可以通过ParseTreeVisitorFactory类获取不同的SQLStatement了,到这里SQLParserEngine解析就分析完了。
SQLParserEngine解析器使用的入口在哪里呢?对于分库分表,ShardingStatement是执行SQL的类,对应JDBC中的Statement类,在《shardingsphere源码阅读-兼容jdbc规范》中分析到,shardingsphere兼容了原生的JDBC的规范,使用使用shardingsphere操作数据库跟原生JDBC操作数据库几乎完全一样。
ShardingStatement的prepare方法如下:
private ExecutionContext prepare(final String sql) throws SQLException {
statementExecutor.clear();
//获取分库分表的运行时上下文
ShardingRuntimeContext runtimeContext = connection.getRuntimeContext();
//从ShardingRuntimeContext获取SQL执行引擎SQLParserEngine作为参数创建SimpleQueryPrepareEngine
BasePrepareEngine prepareEngine = new SimpleQueryPrepareEngine(
runtimeContext.getRule().toRules(), runtimeContext.getProperties(), runtimeContext.getMetaData(), runtimeContext.getSqlParserEngine());
ExecutionContext result = prepareEngine.prepare(sql, Collections.emptyList());
statementExecutor.init(result);
statementExecutor.getStatements().forEach(this::replayMethodsInvocation);
return result;
}ShardingStatement类的prepare方法中,使用SQLParserEngine作为参数创建SimpleQueryPrepareEngine,SimpleQueryPrepareEngine是简单查询准备引擎,这个SimpleQueryPrepareEngine的作用是在真正执行SQL执行之前,先准备好SQL执行所需要的东西。如SQL路由的结果,SQL重写的结果。这里就不具体进行展开分析SimpleQueryPrepareEngine,后面在分析SQL路由,SQL重写会进行展开分析。