lucene学习
数据查询算法
顺序扫描
所谓顺序扫描,例如要找内容包含一个字符串的文件,就是一个文档一个文档的看,对于每一个文档从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接看下一个文件,直到扫描完所有的文件
优点:查询准确率高
缺点:查询速度也会随着数据量的增大越来越大
比如:
- 数据库中的like关键字模糊查询
- 文本编辑器的ctrl+f查询功能
倒排索引
描述
查询前会将查询的内容提取出来组成文档(正文),对文档进行分词组成索引(目录),所以和文档有关联关系,查询的时候先查询索引,通过索引找文档的这个过程叫做全文检索
切分词就是将一句一句话切分成一个词,去掉停用词,去(的,地,得,a,an,the等).去掉空格,去掉标点符号,大写字母转成小写字母,去掉重复的词
为什么倒序索引比顺序扫描快
因为索引可以去掉重复的词,汉语常用的字词大概等于,字典+词典,常用的英文在牛津词典也有收录.如果用计算机速度查询,字典+词典+牛津词典这些内容是非常快的,但是用这些字典,词典组成的文章确实千千万万,不计其数.所以的大小最多也就是字典+词典.所以通过查询所以,和文档的关联关系找到文档速度比较快.顺序扫描法是直接去逐个查询不计其数的文章就算是计算速度也会很慢
优点:查询准确率高,查询速度快并不会因为查询内容的增加速度逐渐变慢
缺点:所以导致文件会额外占用磁盘空间,也就是磁盘量会增大
使用场景:海量数据查询
应用场景
站内搜索:贴吧,论坛,京东,淘宝
垂直领域(818工作网)
专业搜索引擎公司(google,baidu)
lucene介绍
计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式
lucene是apche基金会4炫目的一个子项目,是一个开源代码的全问检索引擎工具包,但不是一个完整的全文检索引擎,而是一个全问检索引擎架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文和德文俩种语言)
lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现全文检索功能,或者是以此为基础建立起完美的全文检索引擎
检索和搜索流程
流程图
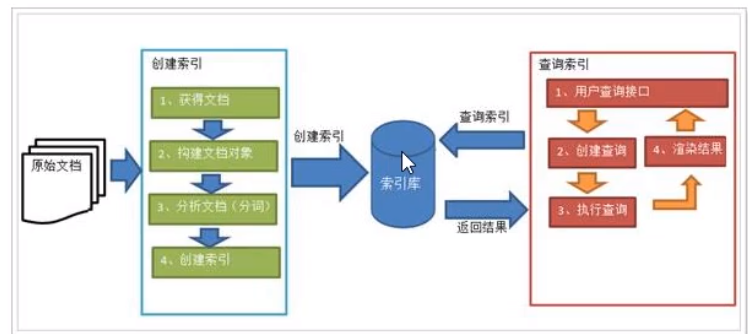
绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括
确定原始内容即要搜索的内容
- 获得文档
- 创建文档
- 分析文档
- 索引文档
红色表示搜索过程,从索引库中搜索内容
- 创建查询
- 执行搜索,从索引库中搜索
- 渲染搜索结果
索引流程
对文档索引的过程,将用户要搜索的文档内容进行索引,索引存储在索引库(index)中
原始内容
原始内容是指要索引和搜索的内容
原始内容包括互联网上的网页,数据库中的数据,磁盘上的文件等
采集数据
从互联网上,数据库,文件系统中等获取需要搜索的原始信息,这个过程就是信息采集,采集数据的目的是为了对原始内容进行索引
采集数据分类
创建文档
获取原始内容是为了索引,在索引前需要将原始内容创建成文档(Document),文档中包括一个一个的域Field,域中存储内容
这里我们可以将磁盘上的一个文件当成一个document,document中包括一些field

每个document可以有多个filed,不同的document可以有不同的field.同一个document可以有相同的field(域名和值域都相同)
分析文档
将原始内容创建为包含域(Field)的文档(document),需要再对域中的内容进行分析,分析成为一个一个的单词
索引文档
对所有文档分析得出的词汇单元进行索引,最终要实现只搜索被所以的语汇单元从而找到document
创建索引是对语汇单元索引,通过词语找文档,这种索引的结构叫倒排索引结构

搜索流程
搜索就是用户输入关键字,从索引中进行搜索的过程.根据关键字搜索索引,根据索引找到对应的文档,从而找到要搜索的内容
用户搜索
全问搜索系统提供用户界面,提交用户搜索的关键词
创建查询
用户查询关键字执行搜索之前需要构建一个查询对象,查询对象中可以指定要查询的关键字,要搜索的field文档等,查询对象会生成具体的查询语法.比如
name:手机,表示搜索name这个field域中,内容为手机的文档
name:华为 and 手机 :表示搜索即包括关键字华为并且也包括手机的文档
执行搜索
搜索引擎过程
根据查询的语法在倒排索引词典表中分别找出对应搜索词的索引,从而找到索引锁链接的文档链表
例如搜索语法为name:华为 and 手机 表示搜索的文档中既要包括华为,也要包括手机
and为交集,or为并集
渲染结果
展示查询结果给用户
Filed域
field是文档中的域,包括field名和field值俩部分,一个文档可以包括多个field,Document只是field的一个承载体,field值为要索引的内容,也是搜索的内容
是否分词
是:做分词处理,将field值进行分词,分词的目的是为了索引
比如商品名称,商品描述等,这些内容用户要输入关键词进行搜索,由于搜索的内容格式大,内容需要分词后将语汇单元建立
否:不做分词 比如商品id,订单号,身份证号等
是否索引
是:进索引.将field分词后的词或整个field值进行索引,存储到索引域,索引的目的是为了搜索
比如商品名称,商品描述分析后进行索引,订单号,身份证号不用分词但也要索引,这些将来都要作为查询条件
不索引:比如图片,文件路径,不用作为查询条件的不用索引
是否存储
是:将field值存储在文档域中,存储在文档域中的field才可以从document中获取
比如:商品名称,订单号,凡是要从document中获取的field都要存储
否:不存储field值
商品描述,内容较大不用存储.如果要向用户展示商品描述可以从系统的关系数据库中获取