并发编程JUC分析2
1.8新加入的原子类
- DubleAccumulator:一个或多个变量共同维护使用提供的函数更新运行double只
- DoubleAdder:一个或多个变量共同维持最初的零和double总和
- LongAccumulator:一个或多个变量共同维护使用提供的函数运行的long值
- LongAdder:一个或多个变量共同维护最初为零综合为long
阿里java开发手册:如果是count++操作,使用AtomicInteger count=new AtimicInteger();count.addAndGet(1),如果是jdk8推荐使用longAdder对象,比AtimicLong性能更好(减少乐观锁的重试次数)
LongAdder为例
当多个线程更新用于收集系统信息,但不用于粒度同步控制的目的公共和时,此类通常由于AtomicLong.在低更新争用下,这俩个类具有相似特征.但在高争用情况下,这一类的吞吐量明显更高,但是代价是空间消耗更高
常用api
- void add(long x) 将当前value+x
- void increment() 当前value+1
- void decrement() 当前value-1
- long sum() 返回当前值,特别注意,在没有并发更新value的情况下,sum会返回一个精确值,存在并发的情况下,sum不保证返回精确值
- void reset 将value重置为0 ,可用于替代重新new 一个LongAdder,但此方法只可以在没有并发更新的情况下使用
- long sumThenReset 获取当前value,并将value重置为0
LongAdder只能计算加法且只能从0开始计算
LongAccumulator
使用给定的累加器函数和标识元素创建新实例
public class Test1 {
volatile static boolean flag=true;
public static void main(String[] args) throws InterruptedException {
LongAdder longAdder = new LongAdder();
longAdder.increment();
longAdder.increment();
System.out.println(longAdder.sum());//2
LongAccumulator longAccumulator = new LongAccumulator((x, y) -> x * y * y, 10);
longAccumulator.accumulate(1);
longAccumulator.accumulate(4);
System.out.println(longAccumulator.get());//160
}
}源码
longAdder只能用来计算加法,且从零开始计算
longAccumulator提供了自定义的函数操作
LongAdder是Striped64的子类
Striped64继承了Number类
其中有这样几个变量
@sun.misc.Contended static final class Cell {
volatile long value;
Cell(long x) { value = x; }
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long valueOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> ak = Cell.class;
valueOffset = UNSAFE.objectFieldOffset
(ak.getDeclaredField("value"));
} catch (Exception e) {
throw new Error(e);
}
}
}
//cpu数量
/** Number of CPUS, to place bound on table size */
static final int NCPU = Runtime.getRuntime().availableProcessors();
//cells数组为2的幂,2,4,8 方便以后位运算
/**
* Table of cells. When non-null, size is a power of 2.
*/
transient volatile Cell[] cells;
//基础的value值,当并发较低时,只累加该值主要用于没有竞争的情况,通过cas更新
/**
* Base value, used mainly when there is no contention, but also as
* a fallback during table initialization races. Updated via CAS.
*/
transient volatile long base;
//创建或者扩容cells数组时使用自旋锁调整单元格的大小(扩容)创建单元格时使用锁
/**
* Spinlock (locked via CAS) used when resizing and/or creating Cells.
*/
transient volatile int cellsBusy;LongAdder的基本思路就是分散热点,将value值分散到一个cell数组中,不同线程会命中到数组不同槽中,各个线程只对自己槽中的那个值进行cas操作,这样热点就被分散了,冲突的概率就小了很多.如果要获取真正的long值,只要将各个槽中的变量值累加返回
sum()会将所有cell数组中的value和 base作为累加值,核心思想就是将之前一个AtomicLong一个value的更新压力分散到多个value中去,从而降级更新热点
低并发时,直接累加到base变量上,高并发时累加进各个线程自己的槽Cell[i]中
对象布局
在hotspot虚拟机里,对象在堆内存中的存储布局可以划分为三个部分,对象头(Header),实例数据(Instance Data)和对齐填充(保证8字节的倍数)

新创建的对象会在堆中的eden区中

对象头
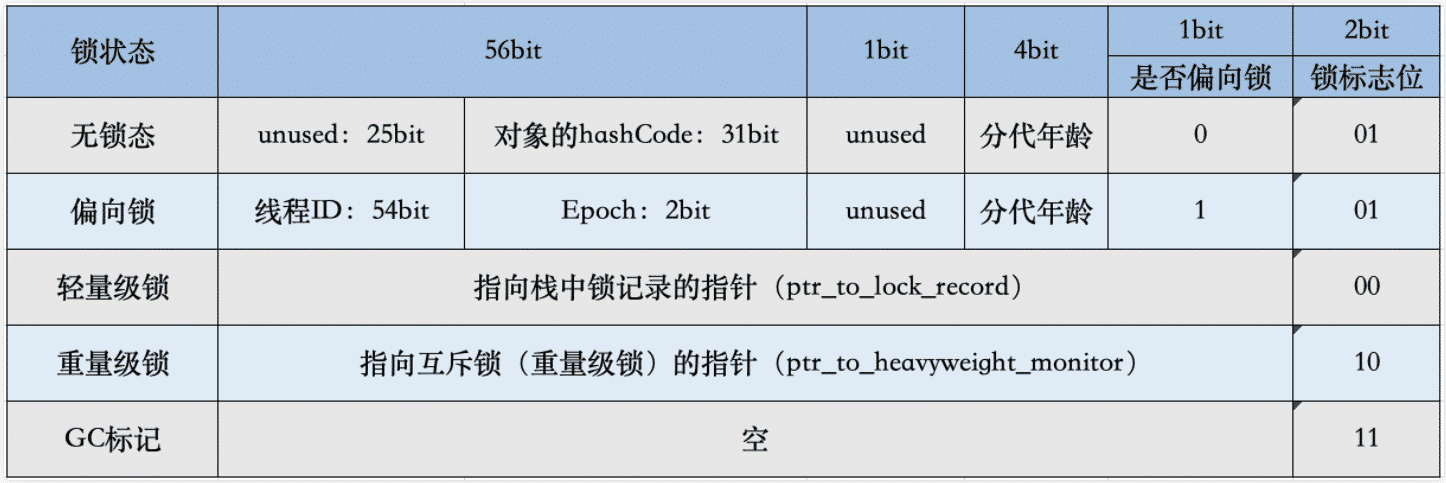
MarkWord
对象标记 Mark Word在openJDK中也叫做markOOP
- 对象哈希码
- 分代年龄最高15,
- 指向锁记录指针
偏向线程id,偏向时间戳
在64位系统中,mark Word占了8个字节,类型指针占了8字节,一共是16个字节

类型指针
类型指针 class pointer在openJDK也叫做classOOP类元信息和类型信息
指向了方法指针的Klass类元信息
对象头mark word占了8字节,类型指针占了8字节,一共是16字节
实例数据
存放类属性(Field)数据信息,包括父类的属性信息
对其填充
虚拟机要求对象的起始地址必须是8字节的整数倍,填充数据不是必须存在的,仅仅是为了字节对其这部分内存,按8字节补充对其(忽略压缩指针)
默认new一个Object是16字节,或者没有任何实例数据的对象都是(在64位java中默认是开启指针压缩的情况下)
分析工具
JOL
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>public static void main(String[] args) throws IOException {
// A a = new A();
//vm的细节详细情况
System.out.println(VM.current().details());
//所有对象都是8字节的整数倍
System.out.println(VM.current().details());
}查看对象的内存占用和布局
public class Test {
public static void main(String[] args) throws IOException {
A a = new A();
System.out.println(ClassLayout.parseInstance(a).toPrintable());
}
}
class A{
boolean a;
}对象头12字节,数据1字节,一共13字节,对其填充到16字节
输出内容
test.A object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 43 c1 00 f8 (01000011 11000001 00000000 11111000) (-134168253)
12 1 byte A.a 0
13 3 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 3 bytes external = 3 bytes total压缩指针
默认开启,为了更小的内存占用
java -XX:+PrintCommandLineFlags -version 查看java虚拟机启动时携带的参数
开启后会让类型指针也占到8字节8+8=16这时候不需要对齐填充就有16字节
AQS
AbstractQueuedSynchronizer抽象队列同步器
简介
AQS在jdk1.5中引入继承了AbstractOwnableSynchronizer
是用来实现锁或者其他同步器组件的公共基础部分的抽象实现
是重量级基础框架以及整个JUC体系的基石,主要用于解决锁分配给谁的问题
官方解释:整体就是一个抽象的FIFO(first in first out 先进先出)队列来完成资源获取线程的排队工作,并通过一个int类变量表示持有锁的状态
整体就是一个抽象的FIFO队列来完成资源获取线程的排队工作,并通过一个int类变量表示持有锁的状态

ReentrantLock,CountDownLatch,ReentrantReadWriteLock,Semaphore 底层都是AQS
比如ReentrantLock有个静态内部类就继承了AQS
锁面向使用者,同步器面向锁的实现者
java大神DougLee提出同意规范并简化了锁的实现,将其抽象出来.屏蔽了同步状态管理,同步队列的管理和维护,阻塞线程排队和通知,唤醒机制等,是一切锁和同步组件实现的----公共基础部分
加锁会导致阻塞,有阻塞就需要排队,实现排队必然需要队列
如果共享资源被占用,就需要一定的阻塞等待唤醒来保证锁分配.这个机制主要用的是CLH队列的变体实现的,将暂时获取不到锁的线程加入到队列中,这个队列就是AQS同步队列的抽象表现.它将要请求共享资源的线程即自身的等待状态封装成队列的节点对象(Node),通过CAS,自旋以及LockSupport.park()的方式,维护state变量的状态,使并发达到同步效果
AQS使用一个volatile的int类型的成员变量来表示同步状态,通过内置的FIFO队列来完成资源获取的排队工作,将每条要去抢占资源的线程封装成一个node节点来实现分配,通过CAS完成对State值的修改

内部源码
private volatile int state;AQS的同步状态state成员变量

公平锁:公平锁讲究先来先到,线程在获取时,如果这个锁的等待队列中已经有线程在等待,那么当前线程就会进入等待队列中
非公平锁:不管是否有等待队列,如果可以获取锁,立刻占有锁对象.也就是说队列的第一个排线程苏醒后,不一定就是排头的这个线程获得锁,它还是需要参加竞争锁(存在线程竞争的情况下),后来的线程可能不讲武德插队夺锁了
公平与非公平锁的唯一区别就在于公平锁在获取同步状态时多了一个限制条件
hasQueuedPredecessors()是公平锁加锁时判断队列中是否存在有效节点的方法
ReentrantReadWriteLock
底层也是AQS,读写锁定义为,一个资源能够被多个读线程访问或者被一个写线程访问,但是不能同时存在读写线程
读写互斥,读读共享
ReentrantReadWriteLock锁降级(类似linux文件读写权限理解,就像写权限要高于读权限一样)锁的严苛程度变强叫做升级,反之叫做降级
| 特性 | 说明 |
|---|---|
| 公平性选择 | 支持非公平(默认),和公平锁的获取方式,吞吐量还是非公平优于公平 |
| 重进入 | 该锁支持重入,以读线程为例:读线程在获取了读锁之后,能够再次获取读锁.写线程在获取了写锁之后能再次获取写锁,同时也可以获取读锁 |
| 锁降级 | 遵循获取写锁,获取读锁再释放的次序,写锁能够降级成为读锁 |
写锁降级为了读锁
- 如果同一个线程持有了写锁,在没有释放写锁的情况下,它还可以继续获得读锁.这就是写锁的降级,降级为了读锁
- 规则管理,先获取写锁,然后获取读锁,在释放写锁的次序
- 如果释放了写锁,那么久完全转换为读锁
锁降级是为了让当前线程感知到数据的变化,目的是保证数据可见性
public class Main2 {
public static void main(String[] args) {
ReentrantReadWriteLock reentrantReadWriteLock = new ReentrantReadWriteLock();
ReentrantReadWriteLock.ReadLock readLock = reentrantReadWriteLock.readLock();
ReentrantReadWriteLock.WriteLock writeLock = reentrantReadWriteLock.writeLock();
//写后读,没问题
writeLock.lock();
System.out.println("写入");
readLock.lock();
System.out.println("读取");
writeLock.unlock();
readLock.unlock();
}
}写后可以读,读后不能写(在读锁unlock之前不能获取写锁,会卡死)不可以锁升级
代码中声明了一个volatile类型的cacheValid变量保证其可见性
首先获取读锁,如果catch不可用,则释放读锁,获取写锁,在更改数据之前,再检查一次cacheValid的值,然后修改数据,讲cacheValid设置为true,然后在释放写锁钱like抢夺获取读锁,此时cache中数据可用,处理cache中数据,最后释放读锁.这个过程就是一个完整的锁降级过程,目的是保证数据的可见性
一句话,同一个线程自己持有写锁时再去拿读锁,本质上相当于重入
写完之后读不应该释放锁,应该直接获取读锁,进行锁降级
synchronized能否降级
不存在竞争的情况下,同一个线程只要判断一下偏向线程的id,是否是自己的线程直接重入就好了,但偏向锁产生竞争性能比轻量级锁还高
jvm可以选择开启偏向锁或者不开启偏向锁.

轻量级锁占用了那么长一段字节,里面的对象分代年龄信息都没了,实际上在线程进入轻量级锁的时候,会在本地的战帧中去拷贝一份无锁状态下的markWord信息,退出轻量级锁的时候,会将对象的markword信息进行还原,变为无锁状态

所以轻量级锁能升级重量级锁,同时也可以还原成无锁状态
只要偏向锁一旦膨胀成轻量级锁,之后就是轻量级锁和无锁的不断切换,就再也不会回到偏向锁状态(因为偏向锁的竞争比轻量级锁更加小号性能)
重量级锁在某些场景下也是能还原成无锁状态的
StampedLock
邮戳锁也叫票据锁
StampedLock是java1.8中新增的一个锁,也是对JDK1.5的读写锁ReentrantReadWrite的优化
stamp(戳记,long类型)代表了锁的状态,当返回为0时,表示线程获取锁失败.并且当释放锁患者转换锁的时候,都要传入最初获取的stamp的值
锁饥饿问题
ReentrantReadWriteLock实现了读写分离,但是一旦读操作比较多的时候,想要获取写锁就比较困难了,假如当前1000个现场999度,一个写,有可能999个读线程长时间抢到了锁,你一个写线程就悲剧了,因为当前有可能会一直存在读锁,而无法获取写锁,根本没机会写
如何解决锁饥饿问题?
使用公平策略可以一定程度上的缓解这个问题(公平锁)
简介
ReentrantReadWriteLock的读锁被占用的时候,其他线程尝试获取写锁的时候会被阻塞.
但是stampedLock采取乐观获取锁后,其他线程尝试获取写锁时不会被阻塞,这其实是对于读锁的优化
所以在获取乐观读锁后,还需要对结果进行校验
对短的只读代码,使用乐观锁的模式通常可以减少争用并提高吞吐量
特点
所有获取锁的方法,都要返回一个邮戳stamp,stamp为0表示获取失败,其余都表示成功
所有释放锁的方法,都需要一个邮戳,这个stamp必须是和成功获取锁时得到的stamp一致
stampedLock是不可重入的(如果一个线程也就持有了写锁,再去获取写锁就会导致死锁)
steampedLock有三种访问形式
- reading 读模式悲观:给你和ReentrantReadWriteLock的读锁类似
- writing 写模式 给你和ReentrantReadWriteLock的写锁类似
- Optmistic reading 乐观读模式:无锁机制,类似数据库中的乐观锁,支持读写并发,很乐观认为读取时没人修改,假如被修改再实现升级为悲观读模式
public class Main2 {
static int number = 37;
static StampedLock stampedLock=new StampedLock();
public void write(){
long stamp=stampedLock.writeLock();
System.out.println("写线程准备修改");
try {
number=number+13;
}finally {
stampedLock.unlockWrite(stamp);
}
System.out.println("写线程结束修改");
}
public void read(){
long stamp=stampedLock.readLock();
System.out.println("读线程准备,开始暂停");
for (int i=0;i<4;i++){
try {
TimeUnit.SECONDS.sleep(4);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("读取中");
}
try {
int result=number;
System.out.println("获取成员变量的值");
}finally {
stampedLock.unlockRead(stamp);
}
}
public void tryOptimisticRead(){
long stamp = stampedLock.tryOptimisticRead();
long result=number;
//间隔四秒,乐观的认为读取的时候没有其他线程修改number值
System.out.println("无修改戳记"+stampedLock.validate(stamp));
for (int i=0;i<4;i++){
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("乐观读中");
}
if (!stampedLock.validate(stamp)){
System.out.println("有人修改");
long l = stampedLock.readLock();
try {
System.out.println("升级为悲观读");
result=number;
System.out.println("悲观读后");
}finally {
stampedLock.unlock(l);
}
}
}
public static void main(String[] args) throws InterruptedException {
Main2 resource = new Main2();
new Thread(()->{
resource.tryOptimisticRead();
},"read").start();
TimeUnit.SECONDS.sleep(2);
new Thread(()->{
System.out.println("进入写线程");
resource.write();
},"write").start();
}
}
使用乐观读的时候每次要去校验一次,看看戳记有没有被改过,如果被改过,就升级为悲观读
结果
无修改戳记true
乐观读中
乐观读中
进入写线程
写线程准备修改
写线程结束修改
乐观读中
乐观读中
有人修改
升级为悲观读
悲观读后